

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Zhihang Ren, University of California, Berkeley and these authors contributed equally to this work (Email: peter.zhren@berkeley.edu);
(2) Jefferson Ortega, University of California, Berkeley and these authors contributed equally to this work (Email: jefferson_ortega@berkeley.edu);
(3) Yifan Wang, University of California, Berkeley and these authors contributed equally to this work (Email: wyf020803@berkeley.edu);
(4) Zhimin Chen, University of California, Berkeley (Email: zhimin@berkeley.edu);
(5) Yunhui Guo, University of Texas at Dallas (Email: yunhui.guo@utdallas.edu);
(6) Stella X. Yu, University of California, Berkeley and University of Michigan, Ann Arbor (Email: stellayu@umich.edu);
(7) David Whitney, University of California, Berkeley (Email: dwhitney@berkeley.edu).
Table of Links
- Abstract and Intro
- Related Wok
- VEATIC Dataset
- Experiments
- Discussion
- Conclusion
- More About Stimuli
- Annotation Details
- Outlier Processing
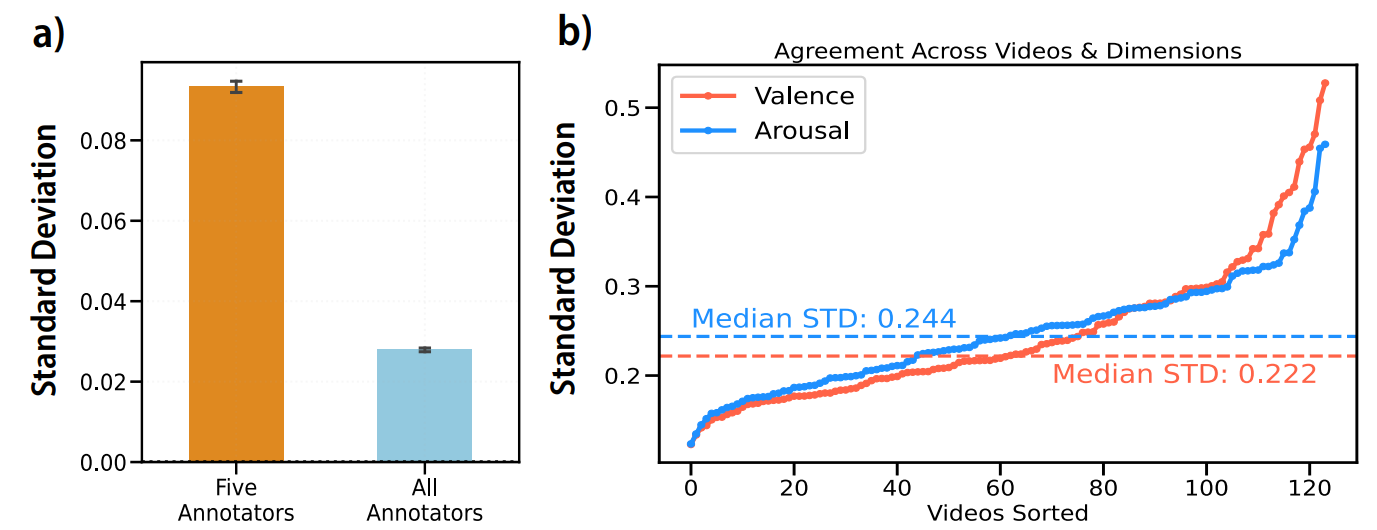
- Subject Agreement Across Videos
- Familiarity and Enjoyment Ratings and References
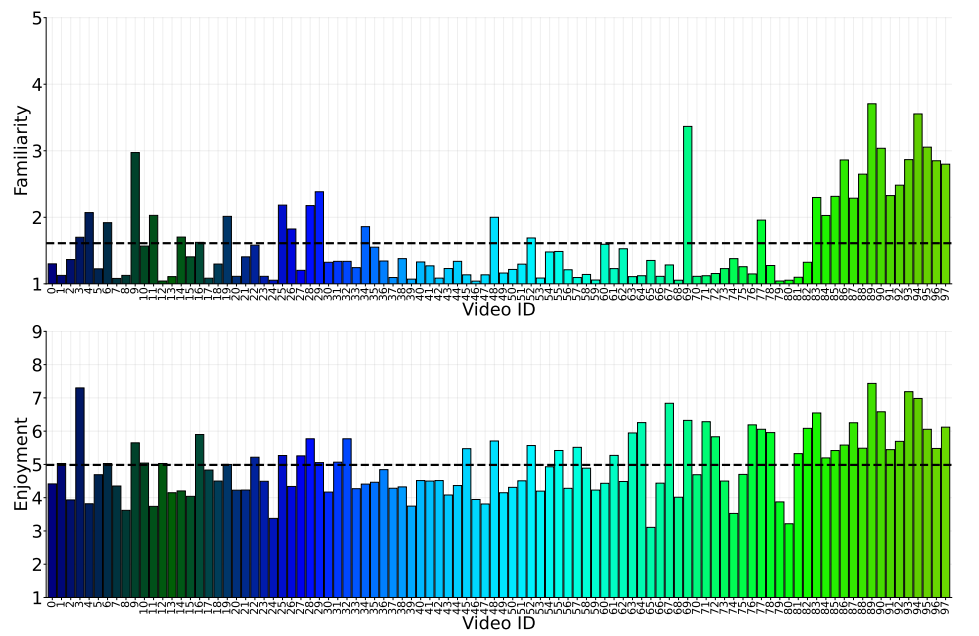
11. Familiarity and Enjoyment Ratings
Familiarity and enjoyment ratings were collected for each video across participants, as shown in Figure 13. Familiarity and enjoyment ratings for video IDs 0-83 were collected in a scale of 1-5 and 1-9, respectively. Familiarity and enjoyment ratings for video IDs 83-123 were collected prior to the planning of the VEATIC dataset and were collected on a different scale. Familiarity and enjoyment ratings for video IDs 83-97 were collected on a scale of 0- 5 and familiarity/enjoyment ratings were not collected for video IDs 98-123. For analysis and visualization purposes, we rescaled the familiarity and enjoyment ratings for video IDs 83-97 to 1-5 and 1-9, respectively, to match video IDs 0-83. To rescale the familiarity values from 0-5 to 1-5 we performed a linear transformation, we first normalized the data between 0 and 1, then we multiplied the values by 4 and added 1. We rescaled the enjoyment values from 0-5 to 1-9 similarly by first normalizing the data between 0 and 1, then we multiplied the values by 8 and added 1. As a result, the average familiarity rating was 1.61 while the average enjoyment rating was 4.98 for video IDs 0-97.
References
[1] Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Luciˇ c, and Cordelia Schmid. Vivit: A video ´ vision transformer. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6836–6846, 2021.
[2] Hillel Aviezer, Shlomo Bentin, Veronica Dudarev, and Ran R Hassin. The automaticity of emotional face-context integration. Emotion, 11(6):1406, 2011.
[3] Simon Baron-Cohen, Sally Wheelwright, Jacqueline Hill, Yogini Raste, and Ian Plumb. The “reading the mind in the eyes” test revised version: a study with normal adults, and adults with asperger syndrome or high-functioning autism. The Journal of Child Psychology and Psychiatry and Allied Disciplines, 42(2):241–251, 2001.
[4] Lisa Feldman Barrett and Elizabeth A Kensinger. Context is routinely encoded during emotion perception. Psychological science, 21(4):595–599, 2010.
[5] Pablo Barros, Nikhil Churamani, Egor Lakomkin, Henrique Siqueira, Alexander Sutherland, and Stefan Wermter. The omg-emotion behavior dataset. In 2018 International Joint Conference on Neural Networks (IJCNN), pages 1–7. IEEE, 2018.
[6] Margaret M Bradley and Peter J Lang. Affective norms for english words (anew): Instruction manual and affective ratings. Technical report, Technical report C-1, the center for research in psychophysiology . . . , 1999.
[7] Marta Calbi, Francesca Siri, Katrin Heimann, Daniel Barratt, Vittorio Gallese, Anna Kolesnikov, and Maria Alessandra Umilta. How context influences the interpretation of fa- ` cial expressions: a source localization high-density eeg study on the “kuleshov effect”. Scientific reports, 9(1):1–16, 2019.
[8] Zhimin Chen and David Whitney. Tracking the affective state of unseen persons. Proceedings of the National Academy of Sciences, 116(15):7559–7564, 2019.
[9] Zhimin Chen and David Whitney. Inferential affective tracking reveals the remarkable speed of context-based emotion perception. Cognition, 208:104549, 2021.
[10] Zhimin Chen and David Whitney. Inferential emotion tracking (iet) reveals the critical role of context in emotion recognition. Emotion, 22(6):1185, 2022.
[11] Kyunghyun Cho, Bart Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. In EMNLP, 2014.
[12] Jules Davidoff. Differences in visual perception: The individual eye. Elsevier, 2012. [13] Abhinav Dhall, Roland Goecke, Simon Lucey, Tom Gedeon, et al. Collecting large, richly annotated facial-expression databases from movies. IEEE multimedia, 19(3):34, 2012.
[14] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
[15] Ellen Douglas-Cowie, Roddy Cowie, Cate Cox, Noam Amir, and Dirk Heylen. The sensitive artificial listener: an induction technique for generating emotionally coloured conversation. In LREC workshop on corpora for research on emotion and affect, pages 1–4. ELRA Paris, 2008.
[16] Paul Ekman. An argument for basic emotions. Cognition & emotion, 6(3-4):169–200, 1992.
[17] Paul Ekman and Wallace V Friesen. Facial action coding system. Environmental Psychology & Nonverbal Behavior, 1978.
[18] Zhiyun Gao, Wentao Zhao, Sha Liu, Zhifen Liu, Chengxiang Yang, and Yong Xu. Facial emotion recognition in schizophrenia. Frontiers in psychiatry, 12:633717, 2021.
[19] Rohit Girdhar, Joao Carreira, Carl Doersch, and Andrew Zisserman. Video action transformer network. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 244–253, 2019.
[20] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision, pages 1026–1034, 2015.
[21] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
[22] Will E Hipson and Saif M Mohammad. Emotion dynamics in movie dialogues. PloS one, 16(9):e0256153, 2021. [23] Sepp Hochreiter and Jurgen Schmidhuber. Long short-term ¨ memory. Neural computation, 9(8):1735–1780, 1997.
[24] John J Hopfield. Neural networks and physical systems with emergent collective computational abilities. Proceedings of the national academy of sciences, 79(8):2554–2558, 1982.
[25] Zhao Kaili, Wen-Sheng Chu, and Honggang Zhang. Deep region and multi-label learning for facial action unit detection. In In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3391–3399, 2016.
[26] Mary Kayyal, Sherri Widen, and James A Russell. Context is more powerful than we think: contextual cues override facial cues even for valence. Emotion, 15(3):287, 2015.
[27] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
[28] Sander Koelstra, Christian Muhl, Mohammad Soleymani, Jong-Seok Lee, Ashkan Yazdani, Touradj Ebrahimi, Thierry Pun, Anton Nijholt, and Ioannis Patras. Deap: A database for emotion analysis; using physiological signals. IEEE transactions on affective computing, 3(1):18–31, 2011.
[29] Dimitrios Kollias and Stefanos Zafeiriou. Aff-wild2: Extending the aff-wild database for affect recognition. arXiv preprint arXiv:1811.07770, 2018.
[30] Dimitrios Kollias and Stefanos Zafeiriou. Expression, affect, action unit recognition: Aff-wild2, multi-task learning and arcface. arXiv preprint arXiv:1910.04855, 2019.
[31] Jean Kossaifi, Georgios Tzimiropoulos, Sinisa Todorovic, and Maja Pantic. Afew-va database for valence and arousal estimation in-the-wild. Image and Vision Computing, 65:23– 36, 2017.
[32] Ronak Kosti, Jose M Alvarez, Adria Recasens, and Agata Lapedriza. Context based emotion recognition using emotic dataset. IEEE transactions on pattern analysis and machine intelligence, 42(11):2755–2766, 2019.
[33] Jiyoung Lee, Seungryong Kim, Sunok Kim, Jungin Park, and Kwanghoon Sohn. Context-aware emotion recognition networks. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10143–10152, 2019.
[34] Tae-Ho Lee, June-Seek Choi, and Yang Seok Cho. Context modulation of facial emotion perception differed by individual difference. PLOS one, 7(3):e32987, 2012.
[35] Yong Li, Jiabei Zeng, Shiguang Shan, and Xilin Chen. Selfsupervised representation learning from videos for facial action unit detection. In Proceedings of the IEEE/CVF Conference on Computer vision and pattern recognition, pages 10924–10933, 2019.
[36] Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. Video swin transformer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3202–3211, 2022.
[37] Cheng Luo, Siyang Song, Weicheng Xie, Linlin Shen, and Hatice Gunes. Learning multi-dimensional edge featurebased au relation graph for facial action unit recognition. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI-22, pages 1239–1246, 2022.
[38] Daniel McDuff, Rana Kaliouby, Thibaud Senechal, May Amr, Jeffrey Cohn, and Rosalind Picard. Affectiva-mit facial expression dataset (am-fed): Naturalistic and spontaneous facial expressions collected. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 881–888, 2013.
[39] Gary McKeown, Michel Valstar, Roddy Cowie, Maja Pantic, and Marc Schroder. The semaine database: Annotated multimodal records of emotionally colored conversations between a person and a limited agent. IEEE transactions on affective computing, 3(1):5–17, 2011.
[40] Trisha Mittal, Pooja Guhan, Uttaran Bhattacharya, Rohan Chandra, Aniket Bera, and Dinesh Manocha. Emoticon: Context-aware multimodal emotion recognition using frege’s principle. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14234– 14243, 2020.
[41] MA Nasri, Mohamed Amine Hmani, Aymen Mtibaa, Dijana Petrovska-Delacretaz, M Ben Slima, and A Ben Hamida. Face emotion recognition from static image based on convolution neural networks. In 2020 5th International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), pages 1–6. IEEE, 2020.
[42] Erik C Nook, Kristen A Lindquist, and Jamil Zaki. A new look at emotion perception: Concepts speed and shape facial emotion recognition. Emotion, 15(5):569, 2015.
[43] Desmond C Ong, Zhengxuan Wu, Zhi-Xuan Tan, Marianne Reddan, Isabella Kahhale, Alison Mattek, and Jamil Zaki. Modeling emotion in complex stories: the stanford emotional narratives dataset. IEEE Transactions on Affective Computing, 12(3):579–594, 2019.
[44] Desmond C Ong, Jamil Zaki, and Noah D Goodman. Computational models of emotion inference in theory of mind: A review and roadmap. Topics in cognitive science, 11(2):338– 357, 2019.
[45] Timea R Partos, Simon J Cropper, and David Rawlings. You don’t see what i see: Individual differences in the perception of meaning from visual stimuli. PloS one, 11(3):e0150615, 2016.
[46] Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Gautam Naik, Erik Cambria, and Rada Mihalcea. Meld: A multimodal multi-party dataset for emotion recognition in conversations. arXiv preprint arXiv:1810.02508, 2018.
[47] Jonathan Posner, James A Russell, and Bradley S Peterson. The circumplex model of affect: An integrative approach to affective neuroscience, cognitive development, and psychopathology. Development and psychopathology, 17(3):715–734, 2005.
[48] Zhihang Ren, Xinyu Li, Dana Pietralla, Mauro Manassi, and David Whitney. Serial dependence in dermatological judgments. Diagnostics, 13(10):1775, 2023.
[49] Fabien Ringeval, Andreas Sonderegger, Juergen Sauer, and Denis Lalanne. Introducing the recola multimodal corpus of remote collaborative and affective interactions. In 2013 10th IEEE international conference and workshops on automatic face and gesture recognition (FG), pages 1–8. IEEE, 2013.
[50] David E Rumelhart, Geoffrey E Hinton, Ronald J Williams, et al. Learning internal representations by error propagation, 1985.
[51] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115:211–252, 2015.
[52] James A Russell. A circumplex model of affect. Journal of personality and social psychology, 39(6):1161, 1980.
[53] James A Russell. dimensional contextual perspective. The psychology of facial expression, page 295, 1997.
[54] Andrey V Savchenko. Facial expression and attributes recognition based on multi-task learning of lightweight neural networks. In 2021 IEEE 19th International Symposium on Intelligent Systems and Informatics (SISY), pages 119–124. IEEE, 2021.
[55] Andrey V Savchenko, Lyudmila V Savchenko, and Ilya Makarov. Classifying emotions and engagement in online learning based on a single facial expression recognition neural network. IEEE Transactions on Affective Computing, 13(4):2132–2143, 2022.
[56] Zhiwen Shao, Zhilei Liu, Jianfei Cai, and Lizhuang Ma. Deep adaptive attention for joint facial action unit detection and face alignment. In Proceedings of the European conference on computer vision (ECCV), pages 705–720, 2018.
[57] Jiahui She, Yibo Hu, Hailin Shi, Jun Wang, Qiu Shen, and Tao Mei. Dive into ambiguity: Latent distribution mining and pairwise uncertainty estimation for facial expression recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6248–6257, 2021.
[58] Ian Sneddon, Margaret McRorie, Gary McKeown, and Jennifer Hanratty. The belfast induced natural emotion database. IEEE Transactions on Affective Computing, 3(1):32–41, 2011.
[59] Mohammad Soleymani, Jeroen Lichtenauer, Thierry Pun, and Maja Pantic. A multimodal database for affect recognition and implicit tagging. IEEE transactions on affective computing, 3(1):42–55, 2011.
[60] Paweł Tarnowski, Marcin Kołodziej, Andrzej Majkowski, and Remigiusz J Rak. Emotion recognition using facial expressions. Procedia Computer Science, 108:1175–1184, 2017.
[61] Y-I Tian, Takeo Kanade, and Jeffrey F Cohn. Recognizing action units for facial expression analysis. IEEE Transactions on pattern analysis and machine intelligence, 23(2):97–115, 2001.
[62] Vedat Tumen, ¨ Omer Faruk S ¨ oylemez, and Burhan Ergen. ¨ Facial emotion recognition on a dataset using convolutional neural network. In 2017 International Artificial Intelligence and Data Processing Symposium (IDAP), pages 1–5. IEEE, 2017.
[63] Gaetano Valenza, Antonio Lanata, and Enzo Pasquale Scilingo. The role of nonlinear dynamics in affective valence and arousal recognition. IEEE transactions on affective computing, 3(2):237–249, 2011.
[64] Raviteja Vemulapalli and Aseem Agarwala. A compact embedding for facial expression similarity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5683–5692, 2019.
[65] Kannan Venkataramanan and Haresh Rengaraj Rajamohan. Emotion recognition from speech. arXiv preprint arXiv:1912.10458, 2019.
[66] Kai Wang, Xiaojiang Peng, Jianfei Yang, Shijian Lu, and Yu Qiao. Suppressing uncertainties for large-scale facial expression recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6897–6906, 2020.
[67] Fanglei Xue, Zichang Tan, Yu Zhu, Zhongsong Ma, and Guodong Guo. Coarse-to-fine cascaded networks with smooth predicting for video facial expression recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2412–2418, 2022.
[68] Seunghyun Yoon, Seokhyun Byun, and Kyomin Jung. Multimodal speech emotion recognition using audio and text. In 2018 IEEE Spoken Language Technology Workshop (SLT), pages 112–118. IEEE, 2018.
[69] Stefanos Zafeiriou, Dimitrios Kollias, Mihalis A Nicolaou, Athanasios Papaioannou, Guoying Zhao, and Irene Kotsia. Aff-wild: valence and arousal’in-the-wild’challenge. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 34–41, 2017.
[70] Yuanyuan Zhang, Jun Du, Zirui Wang, Jianshu Zhang, and Yanhui Tu. Attention based fully convolutional network for speech emotion recognition. In 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pages 1771–1775. IEEE, 2018.
[71] Yuan-Hang Zhang, Rulin Huang, Jiabei Zeng, and Shiguang Shan. M 3 f: Multi-modal continuous valence-arousal estimation in the wild. In 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), pages 632–636. IEEE, 2020.
This paper is available on arxiv under CC 4.0 license.