

Finally! It is time for the 2nd part of my detailed guide on MLOps! Congratulations!
MLOps artifacts
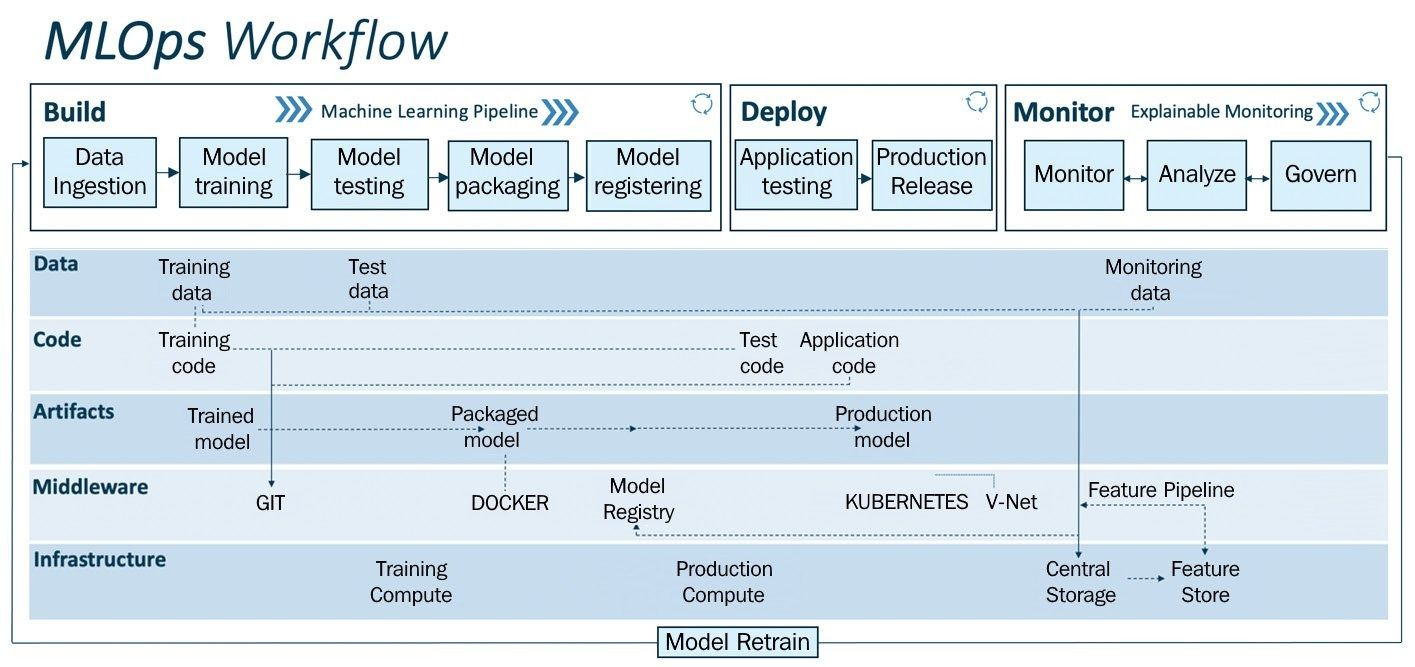
If you regularly read articles on MLOps, you begin to form a particular perception of the context. Thus, the authors of the texts mainly write about working with 3 types of artifacts:
- Data
- Model
- Code
This explains the essence of MLOps. ML-team should create a code base, due to which an automated and repeatable process will be realized:
- Training new versions of ML models on high-quality datasets
- Delivery of updated model versions to end-client services for processing incoming requests
Now, let`s discuss this in more detail.
MLOps: data
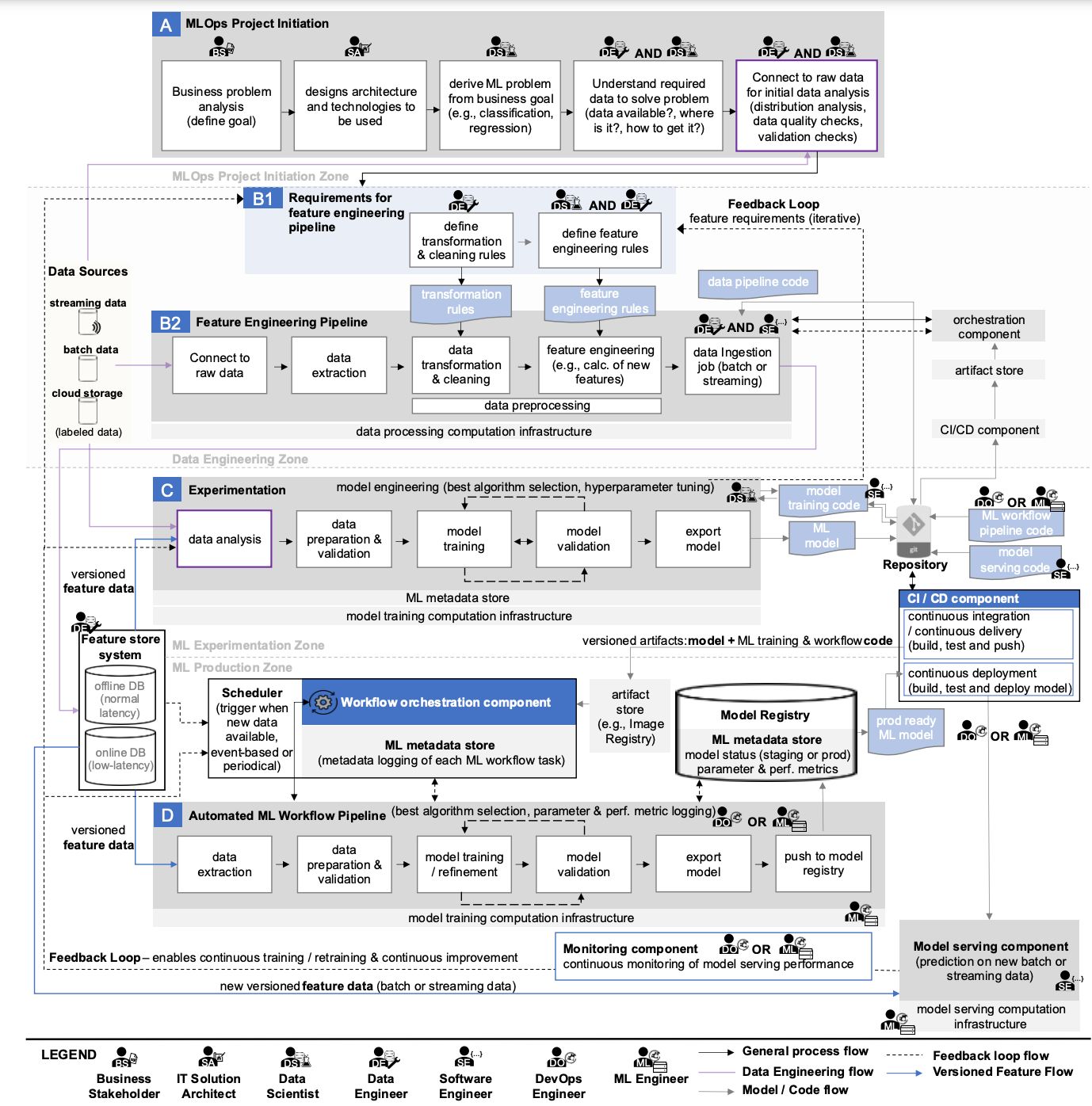
If you have read my previous article, you have already seen this MLOps diagram. Here we can find the following data sources:
- Streaming data
- Batch data
- Cloud data
- Labeled data
- Feature online DB
- Feature offline DB
It is highly debatable to call this list sources, but the conceptual intent seems clear. Some data is stored in a large number of systems and processed in different ways. All of them may be required for an ML model.
How to make sure the correct data gets into the ML system:
- Use tools and processes that will allow you to take data from sources, create datasets from them, and expand them with new features, which are then stored in appropriate databases for general use
- Implement monitoring and control tools because data quality can change
- Add a catalog that will make it easier to search through the data if there is a lot of it
Eventually, the company can have a full-fledged Data Platform with ETL/ELT, data buses, object stores, and other stuff.
The critical aspect of using data within MLOps is automating the preparation of high-quality datasets for training ML models.
MLOps: model
Now, let's look for artifacts that are relevant to ML models:
- ML model
- Prod ready ML model
- Model Registry
- ML Metadata Store
- Model Serving Component
- Model Monitoring Component
Similar to data, you need tools to help:
- Search for the best parameters of ML models by conducting a lot of experiments
- Save the best models and enough information about them into a unique registry (so that it is possible to reproduce the result of experiments in the future)
- Organize delivery of the best models to the final client services
- Monitor the quality of their work to start training new models if necessary automatically
A key aspect of working with models within MLOps is automating the process of retraining models to achieve better quality metrics of their performance on customer queries.
MLOps: code
Code is the easiest. It just automates the processes of working with data and models.
We can find the following artifacts relevant to the code:
- Data transformation rules
- Feature engineering rules
- Data pipeline code
- Model training code
- ML workflow code
- Model serving code
You can only add infrastructure as a code (IaaC), with which all the necessary infrastructure is lifted.
It should be noted that sometimes there is additional code for orchestration, mainly if multiple orchestrators are used in a team. For example, Airflow, which runs the DAG in Dagster.
Infrastructure for MLOps
In this image, I see several types of computing infrastructure in use:
- Data processing computational infrastructure
- Model training computational infrastructure
- Model serving computational infrastructure
Moreover, the model serving computational infrastructure is used both for conducting experiments and retraining models within the automated pipelines' framework. This approach is possible if the utilization of computational infrastructure has a reserve for the simultaneous execution of these processes.
In the first stages, all tasks can be solved within one infrastructure, but the need for new capacities will grow in the future. In particular, due to the specific requirements for configurations of computing resources:
- For model training and retraining, it is not necessary to use the highest-performance Tesla A100 GPUs. You can choose a more straightforward option - the Tesla A30. You can also select GPUs from the RTX A-Series (A2000, A4000, A5000).
- For Serving, Nvidia has a Tesla A2 GPU, which will work if your model and the data portion to be processed do not exceed the size of its video memory. If they do, choose from the RTX A-Series (A2000, A4000, A5000).
- Data processing may not require a graphics card at all, as this process can be CPU-based. However, the choice is even more complicated. You can consider AMD Epyc, Intel Xeon Gold, or modern desktop processors.
The ubiquity of Kubernetes as an infrastructure platform for ML systems adds to the complexity. All computational resources need to be able to be utilized in k8s.
The big scheme of MLOps is just the top level of abstraction that we have to deal with.
Reasonable and Medium Scale MLOps
After looking at such an extensive MLOps scheme and the artifacts mentioned above, there is no desire to build something similar in your own company. You have to select and implement many tools, prepare the necessary infrastructure for them, teach the team how to work with all of this and maintain all of the above.
The most essential thing in MLOps is to get started. You should only implement some MLOps components at a time if there is no business need for them. Guided by maturity models, you can create a base around which the ML platform will be developed in the future.
It is likely that many components will never be needed to achieve business goals. This idea is already being actively promoted in various articles about reasonable-scale MLOps and medium-scale MLOps.
What is the difference between MLOps and ModelOps?
Let's mention ModelOps. Is it part of MLOps or is it MLOps part of ModelOps? Here's an article that does a great job of answering that question.
MLOps as an information system
Viewing the MLOps platform as a simple set of ML software components is tempting. It shouldn't. There are many important aspects whose implementation directly affects the performance of all ML processes.
As a whole model, we can refer to the concept of an information system. If we study the architectural aspects of information systems, we can arrive at the following set of their constituent elements:
- Hardware
- Software
- Data
- Networks
- People
- Procedures
I want to add one more element - knowledge, but it is more about preserving the experience of the team in the process of building and operating the ML platform. It is great when employees have built a platform and successfully use it. It is great when this experience can be passed on to new employees, and they will be able to develop the platform further. And they will understand what decisions were made during its development and why.
To describe the complexity of the ML platform in more detail, it is necessary to consider each information system element.
MLOps: hardware
Not all market players consciously approach the choice of hardware for the ML-system. This is especially noticeable in terms of GPU selection. Often, the hardware on which the pipeline is built is used. Then this pattern just flows into the following projects. However, this is sometimes good. For example, it is justified if it is costly to rewrite the pipeline.
If a small company can buy a server for ML, it will most likely choose a machine with a consumer GPU (RTX 2000/3000).
Now let's analyze this choice:
- For not the most resource-intensive tasks, such servers are fine.
- If there is a need for a large amount of video memory, difficulties arise immediately. It should be considered that the model and some amount of data for it should fit into the memory. You can adjust the size of the data portion for training or inference to fit into the allotted space.
- If the weight of the model reaches tens of gigabytes (for example, a company is developing voice robots) and the data for it needs to be delivered, the selected server will not be suitable. There are 3 popular alternatives: the Nvidia Tesla A30 (24 GB) and the Nvidia Tesla A100 (40 and 80 GB). If that's not enough, you can use NVLink or NVSwitch to connect multiple GPUs.
GPU memory is understood. But how do you select CPU and RAM?
MLOps: CPU and RAM
You can look at examples of server configurations from providers, but this does not guarantee that they will be suitable for the company's specific tasks. Surveys of companies show that the size of RAM is adjusted to the size of the maximum dataset to increase the speed of its loading into the GPU. GPU is the most expensive resource in a server, so ideally, it should not be idle.
CPU is most often needed for preprocessing and loading data into RAM. Depending on the specifics of the experiment, either all CPU cores or a small part of them may be utilized. Some people allocate from 12 to 24 vCPUs for each high-performance GPU, while 8 is enough for some people. The exact number of cores can be obtained only by experiments.
An additional headache is the need to use the GPU in Kubernetes since it is the de facto standard for implementing ML systems. The headache is the need to turn the GPU into an available resource. With this, it will be possible to use the graphics card. To do this, you must deal with the Nvidia GPU Operator or its separate component - Device Plugin. And while we're at it, annotating nodes with labels correctly is a good idea. Not even all Kubernetes experts have heard about it.

MLOps: software
The conversation about software needs to be divided into several parts:
- ML-specific programs
- Additional programs
ML-specific refers to software solutions that implement parts of the functionality of MLOps schema components. ML part can be described as following software components.
The experimentation process can be built with:
- ClearML
- Kubeflow
- MLFlow
- Guild
- Polyaxon
Automation of model retraining can be implemented using:
- Kubeflow
- ClearML
- Airflow
- Dagster
- Prefect
Serving and Deploying models can be implemented using:
- Seldon Core
- KServe
- BentoML
If a project already requires elaborate work with features, the most popular solution is Feast. It has alternatives. However, more often, companies write something of their own, as the performance of ready-made solutions is not enough.
There is a whole stack of ML components that you need to know how to customize, maintain, and operate. The "customize and maintain" part requires the use of additional software. For example:
- Kubernetes - as a container orchestration environment
- KeyCloak - as a single point of user authorization
- Grafana, Prometheus, and Loki - as monitoring and logging tools
- Traefik - as a cluster traffic management tool
- Load balancer for incoming requests to the cluster
In addition, we should remember various security certificates, domain names, databases for used components, cascading caches for datasets, and much more.
Learning and configuring everything on a single system can take a lot of time and effort. Just putting ClearML on a server won't do the trick.
MLOps: data
One more time about data. Here, I will refer to different implementations of existing data storage platforms, so that those interested can learn with MLOps the now fashionable terminological vocabulary of Data engineers.
So, data for ML can be stored in complex architectures:
- Data Warehouse
- Data Lake
- Data Lakehouse
- Data Mesh
Building them takes a considerable amount of resources.
MLOps: network connectivity
Now, Kubernetes clusters are quite often located at a specific provider. Some teams have in-house infrastructure, but even there, it is in a separate server room, quite remote from the group.
The problem is that the data on which the model is trained must be uploaded to a specific server where the training process takes place. If the network channel is not wide enough, you must wait a long time for the necessary data to be loaded. This dramatically increases the waiting time for the results of experiments.
It is necessary to invent different network architectures to make the data transfer faster or to introduce caches into the cluster. If the data is in-house and the computational resources are with the provider, a separate network channel may be required to maintain performance with such a distributed architecture.
MLOps: procedures
Here, you need up-to-date instructions and regulations by which the team will work and new participants will learn.
This is where ITIL comes to mind with its IT Service Management best practices, but there is yet to be an alternative in the world of MLOps. If CRISP-DM already looks outdated, CRISP-ML still needs to be developed. You can find its list of processes, but there needs to be a more detailed description of the methods themselves.
To start with, I can suggest thinking about the following regulations:
- Code versioning (models, experiments, workflows)
- Versioning datasets
- Versioning model files
- Versioning environments
- Metrics logging
- Infrastructure utilization
- Model metrics monitoring
In any case, each team builds its customized processes, even if it initially uses an off-the-shelf approach.

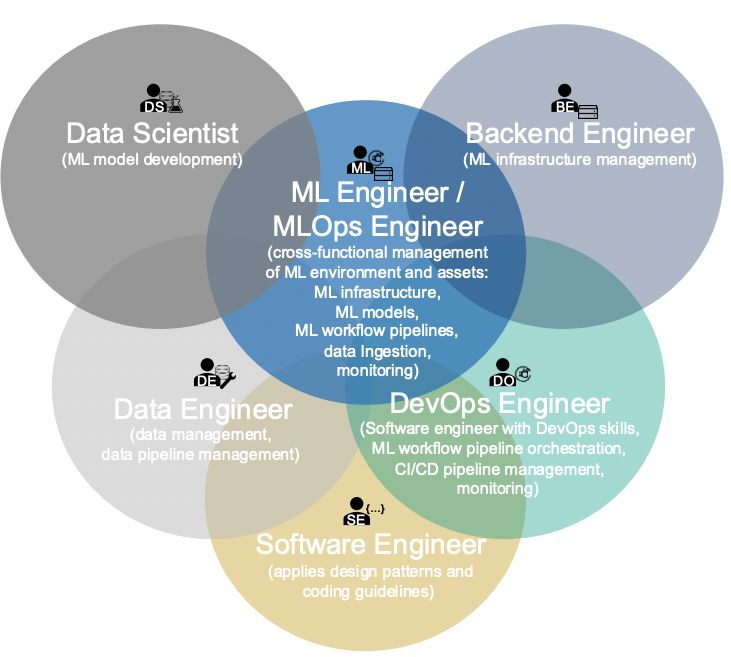
MLOps: team
If you don't have a dedicated role on your command that is responsible for making the ML technology stack work, don't despair. It's still common right now. MLOps engineers can still be considered unicorns for now, almost like Angular developers.
Today, it is more common to give the task of implementing ML systems to DevOps specialists. If they are responsible for CI/CD, let them take over ML pipelines as well. Naturally, this approach has some disadvantages:
- Deploying ML models is different from deploying code
- Serving and Deploy requires knowledge of specific tools
- You need to understand Kubernetes at a high level, and such specialists are worth their weight in gold even without ML
- You need to use IaaS and be friends with Terraform
- The cherry on the cake is the Continuous Training process, which involves writing Python scripts to automate the interaction of different components in orchestrators
At a minimum, DevOps specialists need a lot of time to learn all the processes and technologies. In one version of the ideal world, the MLOps specialist is the next stage of development of a DevOps engineer. It is when all Terraform files have already been written, configured with Ansible, and run in Kubernetes via Argo CD.

It is useful when an MLOps engineer understands the world of ML development, knows the complexities, and can reasonably adjust pipelines. Thus, in another version of the ideal world, an MLOps engineer is an ML developer who is not only willing to teach ML models but also to deal with infrastructure.
Currently, an ideal MLOps-engineer is presented as a "dragon warrior": student, teacher, data scientist, backend developer, ML engineer, data engineer, DevOps, software developer, and the rest in one person. But where to find such a person?
Conclusion
If you made it to the end, you are a strong-minded person who is really interested in ML and MLOps!