
Authors:
(1) Xiao-Yang Liu, Hongyang Yang, Columbia University (xl2427,hy2500@columbia.edu);
(2) Jiechao Gao, University of Virginia (jg5ycn@virginia.edu);
(3) Christina Dan Wang (Corresponding Author), New York University Shanghai (christina.wang@nyu.edu).
Table of Links
2 Related Works and 2.1 Deep Reinforcement Learning Algorithms
2.2 Deep Reinforcement Learning Libraries and 2.3 Deep Reinforcement Learning in Finance
3 The Proposed FinRL Framework and 3.1 Overview of FinRL Framework
3.5 Training-Testing-Trading Pipeline
4 Hands-on Tutorials and Benchmark Performance and 4.1 Backtesting Module
4.2 Baseline Strategies and Trading Metrics
4.5 Use Case II: Portfolio Allocation and 4.6 Use Case III: Cryptocurrencies Trading
5 Ecosystem of FinRL and Conclusions, and References
3.3 Agent Layer
FinRL allows users to plug in and play with standard DRL algorithms, following the unified workflow in Fig. 1. As a backbone, we fine-tune three representative open-source DRL libraries, namely Stable Baseline 3 [37], RLlib [25] and ElegantRL [28]. User can also design new DRL algorithms by adapting existing ones.
3.3.1 Agent APIs. FinRL uses unified Python APIs for training a trading agent. The Python APIs are flexible so that a DRL algorithm can be easily plugged in. To train a DRL trading agent, as in Fig. 2, a user chooses an environment (i,e., StockTradingEnv, StockPortfolioEnv) built on historical data or live trading APIs with default parameters (env_kwargs), and picks a DRL algorithm (e.g., PPO [42]). Then, FinRL initializes the agent class with the environment, sets a DRL algorithm with its default hyperparameters (model_kwargs), then launches a training process and returns a trained model.
The main APIs are given in Table 2, while the details of building an environments, importing an algorithm, and constructing an agents are hidden in the API calls.
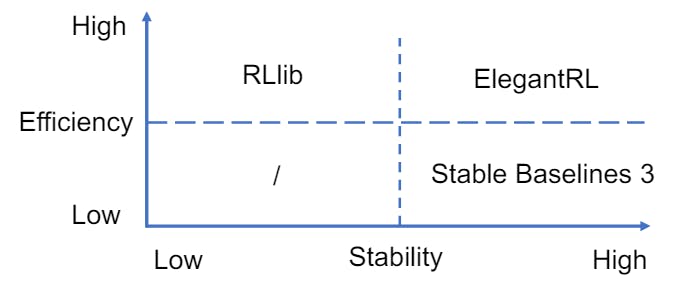
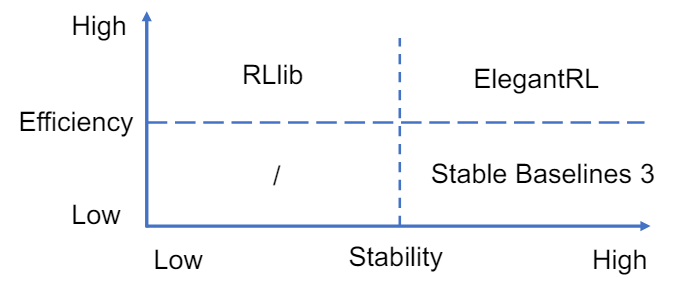
3.3.2 Plug-and-Play DRL Libraries. Fig. 3 compares the three DRL libraries. The details of each library are summarised as follows.
Stable Baselines 3 [37] is a set of improved implementations of DRL algorithms over the OpenAI Baselines [10]. FinRL chooses to support Stable baselines 3 due to its advantages: 1). User-friendly, 2). Easy to replicate, refine, and identify new ideas, and 3). Good documentation. Stable Baselines 3 is used as a base around which new ideas can be added, and as a tool for comparing a new approach against existing ones. The purpose is that the simplicity of these tools will allow beginners to experiment with a more advanced tool set, without being buried in implementation details.
RLlib [25] is an open-source high performance library for a variety of general applications. FinRL chooses to support RLlib due to its advantages: 1). High performance and parallel DRL training framework; 2). Scale training onto large-scale distributed servers; and 3). Allowing the multi-processing technique to efficiently train on laptops. RLlib natively supports TensorFlow, TensorFlow Eager, and PyTorch, but most of its internals are framework agnostic.
ElegantRL [28] is designed for researchers and practitioners with finance-oriented optimizations. FinRL chooses to support ElegantRL due to its advantages: 1). Lightweight: core codes have less than 1,000 lines, less dependable packages, only using PyTorch (train), OpenAI Gym [5] (env), NumPy, Matplotlib (plot); 2). Customization: Due to the completeness and simplicity of the code structure, users can easily customize their own agents; 3). Efficient: Performance is comparable with RLlib [25]; and 4). Stable: As stable as Stable baseline 3 [37].
ElegantRL supports state-of-the-art DRL algorithms, including both discrete and continuous ones, and provides user-friendly tutorials in Jupyter Notebooks. ElegantRL implements DRL algorithms under the Actor-Critic framework, where an agent consists of an actor network and a critic network. The ElegantRL library enables researchers and practitioners to pipeline the disruptive “design, development and deployment” of DRL technology.
Customizing trading strategies. Due to the uniqueness of different financial markets, customization becomes a vital character to design trading strategies. Users are able to select a DRL algorithm and easily customize it for their trading tasks by specifying the state-action-reward tuple in Table 1. We believe that among

the three state-of-the-art DRL libraries, ElegentRL is a practically useful option for financial tasks because of its completeness and simplicity along with its comparable performance with RLlib [25] and stability with Stable Baselines 3 [37].
This paper is available on arxiv under CC BY 4.0 DEED license.