

Introduction
AI-generated music is everywhere. Websites like Udio and Suno allow anyone to create rich, well-constructed pieces of music in many popular genres in seconds. While these websites are absolutely amazing, I would point out that such platforms, in some cases, appear to be trained on large quantities of copyrighted content. But I digress: before the likes of Udio and Suno came into being, simpler - but still interesting - generative music platforms were available. Often, these simpler systems produce sparse melodies, perhaps something akin to ambient music.
This guide explains how to build a simple generative music application (that doesn't infringe on copyrighted music) using a Hidden Markov Model (HMM). You will build the application using a local Jupyter Notebook. A corpus of classical music will be used as input data and will serve as the basis for different experiments with the application.
While a background in music is helpful, it is not essential to complete this guide. I am breaking up the overall exercise into two separate guides: (1) The first guide (i.e. this one) will focus on setting up the application and running a single experiment with it; (2) The second guide will focus on importing/playing your generated music with the freely available Signal Online MIDI Editor along with running additional experiments.
Setting Your Expectations
Before you begin this guide, I want to reiterate: You will not be building anything that comes close to what you can generate on sites like Udio and Suno. Moreover, the model will often generate sequences that may not sound very musical at all! However, despite being a basic model, it is still capable of producing some rather interesting melodies. Non-musicians and musicians alike might utilize these melodies as inspiration for more intricate compositions. If you proceed with this guide and the Part 2 guide, I would encourage you to run multiple experiments to develop different musical sequences that you can use in your own music projects. :-)
Prerequisites and Before You Get Started
To complete the guide, you will need to have:
- An existing local Jupyter notebook environment and basic knowledge working with Jupyter notebooks.
- An existing local Git installation and basic knowledge working with Git.
- Intermediate knowledge of Python.
- Intermediate knowledge of machine learning concepts and familiarity with Hidden Markov Models.
For convenience, I have uploaded a copy of the notebook that you will build to Kaggle, which you can access here. You can download a copy of the notebook to your local computer.
Before you get started with building the notebook, it may be helpful to review the sub-sections directly below. They describe:
- Basic musical concepts.
- The Musical Instrument Digital Interface (MIDI).
- The training dataset.
- The music21 music analysis and computational musicology Python package.
- HMM setup.
Basic Musical Concepts
If you have an existing musical background and are well-grounded in music symbols and music theory, you do not need to review this section.
For those readers without a background in music, I imagine that you've still likely seen a musical score before...something like this:

This is a beginning snippet of the musical score for Handel's The Harmonious Blacksmith in E. It is not necessary for you to understand how to read the score. Instead, we will use it to introduce a few musical concepts that we will rely upon when building our generative model:
- Measures
- Beats
- Notes
- Chords
- Rests
Measures
Music is (generally speaking) composed of individual measures, much as paragraphs are composed of individual sentences. A musical score is a combination of a number of measures. Measures are defined by single vertical lines in musical scores. Looking at the first line of the musical score example above, the green arrows below delineate the measures in that particular line of music:

As seen, there are 3 measures in that first line given that the middle 2 arrows delineate the end of one measure and the beginning of another.
Beats
You've probably caught yourself tapping your foot to the rhythm of a piece of music that you really like. Moreover, you may have discerned that the music seems to follow a certain number of beats, such as "one, two, three, four...one, two, three, four". The measures in a given piece of music will each contain a certain number of beats, e.g. 4. And, at its outset, a score will specify this quantity. Often, you will see something that looks like a fraction at the beginning of musical scores:

For now, you can ignore the bottom number in each "fraction", which are actually known as time signatures. The top number tells us the number of beats in each measure. So, the first time signature specifies there are 2 beats/measure, the second specifies there are 3 beats/measure, the third specifies there are 9 beats/measure, the fourth specifies there are 4 beats/measure, and so on. Four beats per measure is most common and the 4/4 time signature in the figure above is also known as common time. Our example musical score uses common time; it is specified by the mark that looks like a "C", as highlighted by the blue box:

So, our musical example uses 4 beats/measure. A musical score can actually have more than one time signature which might delineate different movements of the musical piece. For our purposes in this guide, we'll stick with "simpler" musical scores that only have one time signature.
Notes
Measures of music need to contain something - namely, music! Musical notes are the most basic musical element and might be conceived of as specific pitches (frequencies) of sound. Notes are represented via a (non-classical) notation using letters: C, D, E, F, G, A, and B. These base letters can be modified as sharp or flat to represent other pitches. Sharp notes are represented using the # symbol, e.g. C#, D#, etc. Flat notes are represented using a symbol that looks like a small b, e.g. Eb, Bb, etc. Some software programs, such as the music21 package discussed below, also represent flat notes with a minus sign -, e.g. E-, B-, etc. As you might already suspect, the small black dots with vertical stems inside the measures of a musical score represent the notes. Referring again to our musical example, I highlighted a handful of notes using purple arrows:

Notes give rise to another important musical concept: keys. A musical key can be thought of as a group of distinct musical notes that sound "good" together. Sharp and flat notes have particular importance with respect to musical keys. A full discussion on musical keys is beyond the scope of this guide, but suffice it to say that notes outside of a musical key will often sound "weird" or "strange". Thus, a composer will typically write a composition in a specific key that uses particular notes. Like time signatures, a composition can be written with more than one key and different keys might delineate different movements or sections of the composition.
You will see notes followed by a number, such as C2, F#3, or E-5. These numbers represent the octave of the note. The idea behind octaves can be visualized with a graphic of a piano keyboard:
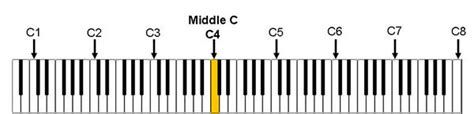
Lower keys on a piano, i.e. to the left, have lower pitches and higher keys, i.e. to the right, have higher pitches. The octave of a note reflects where it is located on the piano keyboard. A lower octave number signifies a lower pitch while a higher octave number signifies a higher pitch.
Unsurprisingly, musical notes can have certain durations within a measure. A note that lasts for an entire measure is known as a whole note; a note that lasts for half of a measure is known as a half note; a note that lasts for one-fourth of a measure is known as a quarter note; a note that lasts for one-eighth of a measure is known as a eighth note; a note that lasts for one-sixteenth of a measure is known as a sixteenth note; and so on. So, with our musical example above where each measure consists of 4 beats, a whole note lasts for 4 beats; a half note lasts for 2 beats; a quarter note lasts for 1 beat; an eighth note lasts for half of a beat; and a sixteenth note lasts for one-fourth of a beat. The duration of a single beat as expressed by a musical note is represented by the bottom number in the time signatures seen in the Beats sub-section above. So, a 4/4 time signature means there are 4 beats per measure and a single beat has the duration of a quarter-note. The symbols used to represent different note durations are not necessary to know to follow this guide, but are generally reflected in how the vertical stems are drawn for each musical note.
Chords
A chord is easily understood: it is two or more musical notes played simultaneously. I highlighted a handful of chords using orange arrows:

Like musical notes, chords have a certain duration.
Rests
A rest is an "empty" space" within a measure where no musical notes or chords are played. Rests have particular durations just like notes and chords. Hence, a whole rest would be the absence of music for an entire measure; a half rest would be the absence of music for half of a measure; a quarter rest would be the absence of music for one-fourth of a measure; and so on. Rests of different durations are denoted by different symbols, which are not necessary to follow this guide. Nonetheless, I highlighted a couple of rests in the musical score example with red arrows:

Summary
The point of this sub-section was to (hopefully) acquaint you with enough musical concepts so that you can successfully complete this Part 1 guide and the upcoming Part 2 guide. There are several music symbols and music theory concepts that I opted to skip over. I encourage you to do a Google search on music symbols and basic music theory to review more comprehensive articles and write-ups.
Musical Instrument Digital Interface (MIDI)
The Musical Instrument Digital Interface (MIDI) is a standard introduced in the early 1980s that allows electronic instruments, such as synthesizers, to exchange data. A couple of simple examples might help to explain the idea:
- You want to perform a musical piece on a synthesizer, and you want to transfer the performance as you are playing it to a computer. In doing so, you can capture the performance and perhaps edit it later on the computer using specialized software. This can be accomplished via a MIDI connection between your synthesizer and your computer.
- In another scenario, you have two synthesizers. You enjoy performing on one of the synthesizers, but you want to use a sound that is only available on the second synthesizer. You can use a MIDI connection between the two synthesizers such that you can play/perform on one synthesizer, but "push" the performance through the second synthesizer's sound bank.
Since MIDI is a digital interface, it "talks" in numbers. For example, different musical notes (i.e. pitches) are represented by different numbers. The full specification for MIDI 1.0, the original MIDI standard introduced in 1983, is quite lengthy. You can read more about the MIDI 1.0 specification here.
Training Dataset
In this Part 1 guide, you will run a single experiment using 5 classical music compositions from the GiantMIDI-Piano dataset, which was released in 2020. This dataset was developed by scientists at ByteDance, the Chinese firm behind the ubiquitous TikTok application. GiantMIDI-Piano is a classical piano MIDI dataset [that] contains 10,855 MIDI files of 2,786 composers. The total duration of GiantMIDI-Piano is 1,237 hours, and there are 34,504,873 transcribed piano notes. To accomplish this feat, the ByteDance scientists designed logic to automatically convert audio recordings of classical piano music to MIDI data. That conversion supports their consumption and analysis via a variety of computational tools. The GitHub repository for the GiantMIDI-Piano dataset is located here. Note that the GitHub repository only contains a small subset of the dataset's full set of MIDI files. Those samples are sufficient for this guide. However, as described in the repository's disclaimer.md file, the full set of MIDI files (~200 MB) can be downloaded from the Google Drive folder located here.
You won't need to use the full GiantMIDI-Piano dataset with this guide. That being said, I've uploaded 10,841 of the original dataset's 10,855 MIDI files to Kaggle. The Kaggle dataset can be accessed here. The 14 missing files are due to errors I encountered when unzipping the original dataset archive. Also, please note that the filenames in the Kaggle dataset are different as compared to the original GiantMIDI-Piano dataset. It was necessary to change the filenames to overcome upload errors due to illegal characters in several original filenames.
music21
music21 offers a comprehensive and powerful set of tools for computer-aided music analysis and computational musicology. Particularly, music21 can be used to analyze and manipulate MIDI data, and to consume/generate MIDI files. You will use music21 to load data from the GiantMIDI-Piano dataset, as well as to generate MIDI files for your generated music. You will only scratch the surface of its capabilities in this guide. The project's full documentation can be viewed/built from the documentation folder of the project's GitHub repository.
HMM Setup
It is assumed you already understand the mechanics of Hidden Markov Models.
The input to the HMM is a sequence of musical-type observations. There are 3 musical types: <REST>, <NOTE>, and <CHORD>. So, a sample sequence of these types could be:
<NOTE> <REST> <CHORD> <NOTE> <NOTE> <NOTE> <CHORD> <REST>...
The HMM predicts a hidden sequence of musical elements from the observation sequence. So, the prediction for the partial sequence above might start out as:
[{'name': '<NOTE>', 'pitch': 'C6', 'duration': 1.0}, {'name': '<REST>', 'duration': 0.25},...]
To determine the hidden sequence of musical elements, the HMM needs to calculate the probability of a particular musical element given an observed musical type over the entire observation sequence. As you know, we can reform this probability calculation to express it as the multiplication of the probability of musical type m having a musical element e and the probability of musical element e_i given a preceeding musical element e_i-1. These probabilities represent our emission and transition probabilities respectively. So, for this HMM, we need to define/calculate:
O = o_1, o_2, ..., o_M, a set of `M` possible observations (i.e. musical types).
π = π_1, π_2, ..., π_N, an initial probabliity distribution that an observation sequence begins with a given state (i.e. musical element) where `N` is the number of states (i.e. musical elements).
A = a_11, a_12, ..., a_NN, a transition probability matrix where `a_ij` is the probability of moving from state (i.e. musical element) `i` to state (i.e. musical element) `j`; each row of `A` sums to 1.
B = b_11, b_12, ..., b_NM, an emission probability matrix where b_ij is the probability of state `i` (i.e. musical element `e_i`) emitting observation (i.e. musical type) `j` (musical type `m_j`).
From the components above, we will derive:
E = e_1, e_2, ..., e_M, a set of `M` hidden states (i.e. musical elements).
Building the Music Generation Jupyter Notebook
You are now ready to start building the music generation notebook. Broadly, the notebook is broken into 3 parts:
- Loading, organizing, and transforming MIDI data.
- Running the transformed MIDI data through a Hidden Markov Model (HMM).
- Exporting the output of the HMM as MIDI data.
Step 1 - Setting Up Your Environment
Step 1a - Cloning GiantMIDI-Piano GitHub Repository
The GiantMIDI-Piano GitHub repository contains a subset of the dataset's full set of MIDI files that will be sufficient for use with this guide. Use git to clone the repository to your local computer:
git clone https://github.com/bytedance/GiantMIDI-Piano.git
Step 1b - Creating a Data Directory for Musical Scores
-
Create a new directory on your local computer. This directory will hold selected GiantMIDI-Piano musical scores that will serve as input data for our first experiment with the HMM. You can name the directory as you wish. This guide uses the name
midi-music. -
Using the
GiantMIDI-Pianorepository that you cloned in Step 1a, navigate toGiantMIDI-Piano/midis_for_evaluation/giantmidi-piano. -
Copy the following 5 MIDI files from
GiantMIDI-Piano/midis_for_evaluation/giantmidi-pianoto the input data directory you just created, e.g.midi-musicif you opted to use that name:
-
Schubert_Fantasie_in_C_major_D760_lR43Ti4w5MM_cut_mov_1.mid -
Schubert_Fantasie_in_C_major_D760_lR43Ti4w5MM_cut_mov_2.mid -
Schubert_Fantasie_in_C_major_D760_lR43Ti4w5MM_cut_mov_3.mid -
Schubert_Fantasie_in_C_major_D760_lR43Ti4w5MM_cut_mov_4.mid
The MIDI files above represent one distinct musical score: Fantasie in C major by Franz Schubert. This is a fairly long composition that is composed of multiple movements or sections. Interestingly, not all sections have the same time signature and musical key. The "C major" designation in the composition name represents the main musical key of the score. If you reviewed the Notes sub-section above, I explained that notes outside of a musical key might sound "weird" or "strange". So, the multiple keys used with this composition could lead to some rather non-musical results. Similarly, the use of multiple time signatures may result in some strange rhythms.
Step 1c - Installing Packages
Install the NumPy and music21 packages using pip:
pip install numpy
pip install music21
- You will use NumPy arrays and numerical methods frequently throughout the notebook.
- As mentioned in the music21 sub-section above, you will use music21 to load MIDI files from the GiantMIDI-Piano dataset, as well as to generate MIDI representations of your generated music.
Step 2 - Building the Music Generation Notebook
The following 23 sub-steps build each of the music generation notebook's 23 cells in order.
Step 2.1 - CELL 1: Importing Python Packages
The first cell imports required Python packages. Set the first cell to:
### CELL 1: Import Python packages ###
import os
from typing import Tuple, Union
# Data and arithmetic packages
import numpy as np
# Music analysis packages
from music21 import *
Step 2.2 - CELL 2: Setting Constants
The second cell sets constants used throughout the notebook. Replace [INSERT_PATH_TO_YOUR_INPUT_DATA_DIRECTORY_HERE] with the directory that you created in Step 1b-1 to hold the MIDI files that will be used as input data.
### CELL 2: Constants ###
DATA_DIR = "[INSERT_PATH_TO_YOUR_INPUT_DATA_DIRECTORY_HERE]" # e.g. "C:/midi-music"
OBS = {
"OBS1": ["<NOTE>", "<CHORD>", "<NOTE>", "<NOTE>", "<REST>", "<NOTE>", "<NOTE>", "<NOTE>", "<CHORD>", "<NOTE>", "<REST>", "<NOTE>", "<NOTE>", "<NOTE>", "<CHORD>"],
"OBS2": ["<CHORD>", "<CHORD>", "<CHORD>", "<CHORD>", "<NOTE>", "<CHORD>", "<CHORD>", "<REST>", "<CHORD>", "<REST>", "<CHORD>", "<REST>", "<NOTE>", "<CHORD>", "<REST>"],
"OBS3": ["<REST>", "<NOTE>", "<REST>", "<NOTE>", "<REST>", "<NOTE>", "<CHORD>", "<NOTE>", "<NOTE>", "<CHORD>", "<REST>", "<NOTE>", "<REST>", "<NOTE>", "<NOTE>"],
"OBS4": ["<REST>", "<NOTE>", "<CHORD>", "<NOTE>", "<CHORD>", "<NOTE>", "<NOTE>", "<REST>", "<CHORD>", "<REST>", "<CHORD>", "<NOTE>", "<NOTE>", "<NOTE>", "<CHORD>"]
}
USE_OBS = OBS["OBS1"]
- The
OBSdictionary holds a set of observations that will be used with the HMM. In other words, these are the sequences that we observe and from which we wish to predict a hidden sequence via the HMM. As you can see, each observation sequence is built from a 3-member set: {<REST>,<NOTE>,<CHORD>}. These items represent the musical types that can comprise a musical sequence for our purposes in this guide. - The
USE_OBSconstant simply refers to a specific observation sequence in theOBSdictionary.
The representations <REST>, <NOTE>, and <CHORD> are chosen arbitrarily. They could have just as easily been represented as <1>, <2>, and <3>. However, I think explicit representations are more useful as they make the guide easier to follow.
Step 2.3 - CELL 3: Utility Function to Load MIDI Data
The third cell defines a utility function that will be used to load MIDI data using the music21 converter.parse method. Set the third cell to:
### CELL 3: Utility function to load MIDI data ###
def load_data() -> list:
scores = []
for filename in os.listdir(DATA_DIR):
if filename.endswith(".mid"):
filepath = DATA_DIR + filename
midi = converter.parse(filepath)
scores.append(midi)
return scores
converteris music21 class for reading different music file formats including MIDI files.
Step 2.4 - CELL 4: Loading MIDI Data
The fourth cell runs the load_data function defined in Step 2.3 to load the MIDI files in your input data directory created in Step 1b.
### CELL 4: Load MIDI Data ###
scores = load_data()
Step 2.5 - CELL 5: Utility Function to Get All Musical Elements and Indices of Measures For Each Score
The fifth cell defines a utility function that "flattens" each MIDI musical score via the music21 recurse method and, in doing so, extracts a list of specific musical elements (i.e. rests, notes, chords) comprising each musical score. It also builds a list of indices pointing to the locations of measures in the scores. Set the fifth cell to:
### CELL 5: Utility function to get all musical elements and indices of measures for each score ###
def get_indices_of_measures_and_musical_elements_by_score(scores: list) -> Tuple[list, list]:
all_scores_elements = []
indices_of_all_measures = []
for score in scores:
elements = [element for element in score.recurse()]
measures = []
for e in range(len(elements)):
if isinstance(elements[e], stream.Measure):
measures.append(e)
indices_of_all_measures.append(measures)
all_scores_elements.append(elements)
return indices_of_all_measures, all_scores_elements
Step 2.6 - CELL 6: Getting All Musical Elements and Indices of Measures For Each Score
The sixth cell runs the get_indices_of_measures_and_musical_elements_by_score function defined in Step 2.5. Set the sixth cell to:
### CELL 6: Getting all musical elements and indices of measures for each score ###
indices_of_all_measures, all_scores_elements = get_indices_of_measures_and_musical_elements_by_score(scores)
-
If you print the returned
indices_of_all_mesaureslist, you should see:
[[2, 6, 21, 51, 61, 81, 91, 117, 138, 161, 188, 211, 232, 269, 301, 315, 324, 343, 349, 362, 386, 392, 405, 418, 424, 426, 453, 473, 493, 529, 569, 602, 642,...
-
If you print the returned
all_scores_elementslist, you should see a sequence of music21 objects:
[[<music21.metadata.Metadata object at 0x25158fc32e0>, <music21.stream.Part 0x2516afb7e50>, <music21.stream.Measure 1 offset=0.0>,...
- The metadata at the beginning of each score is not needed for our purposes in this guide. We will pull out the elements that we need in the next two steps.
Step 2.7 - CELL 7: Utility Function to Extract Musical Properties of Musical Elements by Measure and by Score
The following are examples of a music21 Rest object, a Note object, and a Chord object:
<music21.note.Rest 16th>
<music21.note.Note C#>
<music21.chord.Chord G4 C#5 B-5>
Each musical score contained within the all_scores_elements list from Step 2.6 is composed of these types of music objects. Moreover, each of these music objects has different properties that we can access. For example, they all have a duration property which tells how long (i.e. for how many beats) a given music element lasts. music21 Note objects have a pitch property that tells us the specific note being played. Chord objects have a notes property that tells us which specific notes comprise the chord. The seventh cell defines a utility function that extracts the musical properties of the musical elements in each score. The musical elements are organized by the measure that they belong to in each score. This utility function also returns the average measure length - in terms of number of musical elements - for all scores. Set the seventh cell to:
### CELL 7: Utility function to extract musical properties of musical elements by measure and by score
def extract_musical_elements(all_scores_elements: list, indices_of_all_measures: list) -> dict:
def normalize_duration(duration: Union[float, duration.Duration]) -> float:
_duration = duration
if type(_duration) is not float:
_duration = float(_duration)
return round(_duration, 2)
def normalize_volume(volume: float) -> float:
return round(float(volume), 1)
elements_by_measure_by_score = {}
num_measures = 0
len_all_measures = 0
for s in range(len(all_scores_elements)):
elements_by_measure_by_score[s] = {}
# Extract the musical elements of this score
elements = all_scores_elements[s]
indices = indices_of_all_measures[s]
i = 0 # Measure counter
while True:
measure = []
start = indices[i]
end = indices[i + 1]
for e in range(start + 1, end):
element_props = None
if isinstance(elements[e], note.Rest):
element_props = {"name": "<REST>", "duration": normalize_duration(elements[e].quarterLength)}
if isinstance(elements[e], note.Note):
element_props = {"name": "<NOTE>", "pitch": str(elements[e].pitch), "duration": normalize_duration(elements[e].quarterLength)}
if isinstance(elements[e], chord.Chord):
element_props = {"name": "<CHORD>", "notes": [], "duration": normalize_duration(elements[e].duration.quarterLength)}
for chord_note in elements[e].notes:
element_props["notes"].append(str(chord_note.pitch))
if not element_props == None:
measure.append(element_props)
elements_by_measure_by_score[s][i] = measure
num_measures += 1
len_all_measures += len(measure)
if i + 1 == len(indices_of_all_measures[s]) - 1:
break
else:
i += 1
avg_measure_len = round(len_all_measures/num_measures)
return elements_by_measure_by_score, avg_measure_len
- The
normalize_durationhelper method is used to normalizedurationproperty values, which are sometimes expressed as a float and other times as fractions of a beat. - music21
NoteandChordobjects also have avolumeproperty. I opted to neglect the property at this point in the guide to keep things a bit simpler. This is why thenormalize_volumehelper method is defined but not used.
Step 2.8 - CELL 8: Extracting Musical Properties of Musical Elements by Measure and by Score
The eighth cell runs the extract_musical_elements function defined in Step 2.7. Set the eighth cell to:
elements_by_measure_by_score, avg_measure_len = extract_musical_elements(all_scores_elements, indices_of_all_measures)
- If you print the returned
elements_by_measure_by_scoredictionary, you will see the following output:
{0: {0: [{'name': '<REST>', 'duration': 4.0}], 1: [{'name': '<REST>', 'duration': 1.0}, {'name': '<CHORD>', 'notes': ['C3', 'E3', 'G2', 'C4', 'E4', 'C2'], 'duration': 0.5},...
- If you print
avg_measure_len, you should see that the average measure length is22. You may have also noticed that the length of each observation sequence in Step 2.2 is15. I opted to set the observation sequence length to this value arbitrarily.
Step 2.9 - CELL 9: Utility Function to Generate Dictionary of Unique Elements and their Frequencies
We need to define a "vocabulary" for our input data. In other words, we need to extract the unique elements across all 3 musical scores. Be aware that <NOTE> and <CHORD> elements with the same pitches, but different durations, are themselves different. So, each of the following examples are unique elements:
{'name': '<CHORD>', 'notes': ['G#3', 'C4', 'E-4'], 'duration': 0.75}
{'name': '<CHORD>', 'notes': ['G#3', 'C4', 'E-4'], 'duration': 1.00}
{'name': '<NOTE>', 'pitch': 'G5', 'duration': 0.25}
{'name': '<NOTE>', 'pitch': 'G5', 'duration': 0.50}
Of course, <REST> elements of different durations also represent unique elements. The ninth cell defines a utility function to generate a dictionary of unique elements. It also returns a second dictionary with the frequency of each unique element. Set the ninth cell to:
def get_unique_elements_and_freqs(elements_by_measure_by_score: dict) -> Tuple[dict, dict, dict]:
unique_elems = {}
freqs = {}
key = -1
for score in elements_by_measure_by_score:
for measure in elements_by_measure_by_score[score]:
elements = elements_by_measure_by_score[score][measure]
for element in elements:
if element not in list(unique_elems.values()):
# Create a new key for this element
key += 1
# Add this element to unique elements
unique_elems[key] = element
# Add this element to `freqs` dictionary
freqs[key] = 1
else:
# Get the key for this element
key_for_this_element = list(unique_elems.values()).index(element)
# Update the frequency in the `freqs` dictionary
freqs[key_for_this_element] += 1
return unique_elems, freqs
- As mentioned in Step 2.7, each music21
NoteandChordobjects have avolumeproperty but I opted not to extract it at this point in the guide. This was done to simplify the "vocabulary" of the musical scores. Ifvolumeis extracted as a property,NoteandChordelements with the same pitch and duration values, but different volumes, would themselves be different thus increasing the size of our musical vocabulary and increasing the number of calculations we need to make for the HMM.
Step 2.10 - CELL 10: Generating Dictionary of Unique Elements and their Frequencies
The tenth cell runs the get_unique_elements_and_freqs function defined in Step 2.9. Set the tenth cell to:
### CELL 10: Generating dictionary of unique elements and their frequencies ###
unique_elems, freqs = get_unique_elements_and_freqs(elements_by_measure_by_score)
-
If you print the
unique_elemsdictionary, you will see the following output:
{0: {'name': '<REST>', 'duration': 4.0}, 1: {'name': '<REST>', 'duration': 1.0}, 2: {'name': '<CHORD>', 'notes': ['C3', 'E3', 'G2', 'C4', 'E4', 'C2'],...
-
You can also print the length of the
unique_elemsdictionary which should be5163. -
If you print the
freqsdictionary, you will see the following output:
{0: 1, 1: 273, 2: 1, 3: 1, 4: 1175, 5: 1, 6: 1, 7: 509, 8: 1,...
-
The
freqsdictionary is not used in the setup of the HMM. That being said, you can easily write a function to output the topnunique elements to better understand the structure of this selection of music. It is left as an exercise for you to implement such a function; and it should output the following top 10 unique elements:
# Top 10 musical elements expressed as a tuple (element, frequency)
({'name': '<REST>', 'duration': 0.25}, 1175)
({'name': '<REST>', 'duration': 0.08}, 509)
({'name': '<REST>', 'duration': 0.33}, 437)
({'name': '<REST>', 'duration': 0.5}, 430)
({'name': '<REST>', 'duration': 0.17}, 395)
({'name': '<REST>', 'duration': 0.75}, 311)
({'name': '<REST>', 'duration': 1.0}, 273)
({'name': '<REST>', 'duration': 0.67}, 229)
({'name': '<REST>', 'duration': 0.42}, 203)
({'name': '<REST>', 'duration': 1.25}, 170)
- Additional basic analysis that you can implement should output that there are
44unique<REST>elements,1156unique<NOTE>elements, and3963unique<CHORD>elements.
Step 2.11 - Utility Function to Generate Initial Probability Distribution
We are now ready to start setting up the HMM. In this step, we will calculate an initial probability distribution matrix, I. The matrix tells us the probability of starting a musical sequence with a particular element from unique_elems. The shape of the initial probability distribution matrix is (1, 764). The eleventh cell defines a function to generate I. Set the eleventh cell to:
### CELL 11: Utility function to generate initial probability distribution ###
def calculate_initial_probability_distribution(elements_by_measure_by_score: dict[dict[list]], unique_elems: dict) -> np.ndarray:
num_elements = len(unique_elems)
I = np.zeros((num_elements))
count = 0
for score in elements_by_measure_by_score:
for measure in elements_by_measure_by_score[score]:
first_element = elements_by_measure_by_score[score][measure][0]
first_element_key = list(unique_elems.values()).index(first_element)
I[first_element_key] += 1
count += 1
I = I/count
return I
Step 2.12 - Generating Initial Probability Distribution
The twelfth cell runs the calculate_initial_probability_distribution function defined in Step 2.11. Set the twelfth cell to:
### CELL 12: Generating initial probability distribution ###
I = calculate_initial_probability_distribution(elements_by_measure_by_score, unique_elems)
-
The sum of the initial probabilities should be
1.0which you can check by calling thesummethod onI:
print(I.sum())
# Should output 1.0
Step 2.13 - Utility Function to Generate Transition Probability Matrix
Next, we need to calculate the transition probability matrix, A. The transition probability matrix tells us the probability of "moving" from one particular musical element to another musical element. The shape of the transition probabliity matrix is (5163, 5163). The thirteenth cell defines a utility function to generate A. Set the thirteenth cell to:
### CELL 13: Utility function to generate transition probability matrix ###
def calculate_transition_probability_matrix(elements_by_measure_by_score: dict, unique_elems: dict) -> np.ndarray:
num_elements = len(unique_elems)
A = np.zeros((num_elements, num_elements), dtype = "float32")
for key in range(0, len(unique_elems)):
unique_element = unique_elems[key]
count = 0
for score in elements_by_measure_by_score:
for m_index in range(len(elements_by_measure_by_score[score])):
elements = elements_by_measure_by_score[score][m_index]
for e_index in range(len(elements)):
element = elements[e_index]
if element == unique_element:
count += 1
if e_index < len(elements) - 1:
next_element = elements[e_index + 1]
elif m_index < len(elements_by_measure_by_score[score]) - 1:
next_element = elements_by_measure_by_score[score][m_index + 1][0]
else:
# The last element of the last measure of every score won't have a succeeding musical element.
# Arbitrarily assign `next_element` to a half note rest.
next_element = {'name': '<REST>', 'duration': 2.0}
next_key = list(unique_elems.values()).index(next_element)
A[key, next_key] += 1
A[key, :] = A[key, :]/count
return A
Step 2.14 - Generating Transition Probability Matrix
The fourteenth cell runs the calculate_transition_probability_matrix function defined in Step 2.13. Set the fourteenth cell to:
### CELL 14: Generating transition probability matrix ###
A = calculate_transition_probability_matrix(elements_by_measure_by_score, unique_elems)
- Each row of the transition probability matrix should sum to
1.0. This can be verified by calling thesum()method on each row.
Step 2.15 - CELL 15: Utility Function to Generate Emission Probability Matrix
The emission probability matrix, B, gives us the last set of probabilities that we need to setup the HMM. The emission probability matrix tells us the probability that a given musical element "emits" a given observation. Remember from Step 2.2, we only have 3 possible observation values: <REST>, <NOTE>, and <CHORD>. So, if a musical element is a rest, its probability of emitting the observation <REST> is 1. The same logic applies to notes and chords. The shape of the emission probability matrix is (5163, 15). The fifteenth cell defines a utility function to generate the emission probability matrix. Set the fifteenth cell to:
### CELL 15: Utility function to generate emission probability matrix ###
def calculate_emission_probability_matrix(unique_elems: dict, OBS: list) -> np.ndarray:
num_elements = len(unique_elems)
B = np.zeros((num_elements, len(OBS)), dtype = "float32")
for key in unique_elems:
emitting_element = unique_elems[key]
for o in range(len(OBS)):
observation = OBS[o]
if emitting_element["name"] == observation:
prob = 1
else:
prob = 0
B[key, o] = prob
return B
Step 2.16 - CELL 16: Generating Emission Probability Matrix
The sixteenth cell runs the calculate_emission_probability_matrix function defined in Step 2.15. For this preliminary experiment, we'll use the observation sequence specified by the USE_OBS constant from Step 2.2. Set the sixteenth cell to:
### CELL 16: Generating emission probability matrix ###
B = calculate_emission_probability_matrix(unique_elems, USE_OBS)
Step 2.17 - CELL 17: Utility Function to Implement Viterbi Algorithm
Now that we have the initial probability distribution matrix, the transition probability matrix, and the emission probability matrix, we can calculate the Viterbi lattice for our observation sequence chosen in Step 16. Simultaneously, we will generate the backpointer matrix to read out the best (i.e. highest probability) path from the lattice. Both the Viterbi lattice and backpointer matrix will have shape (5163, 15). The seventeenth cell defines a utility function to generate the Viterbi lattice and the backpointer matrix. Set the seventeenth cell to:
def viterbi(OBS, unique_elems, I, A, B):
states = list(unique_elems.keys())
S = len(states)
T = len(OBS)
viterbi_lattice = np.zeros((S, T))
backpointer_matrix = np.zeros((S, T))
for state in range(len(states)):
prob = I[state] * B[state][0]
viterbi_lattice[state][0] = prob
backpointer_matrix[state][0] = 0
for t in range(1, len(OBS)):
for state in range(0, len(states)):
max_prob = 0
argmax = 0
for state_prior in range(len(states)):
prob = viterbi_lattice[state_prior][t - 1] * A[state_prior][state] * B[state][t]
if prob > max_prob:
max_prob = prob
argmax = state_prior
viterbi_lattice[state][t] = max_prob
backpointer_matrix[state][t] = argmax
return viterbi_lattice, backpointer_matrix
Step 2.18 - CELL 18: Generating Viterbi Lattice and Backpointer Matrix
The eighteenth cell runs the viterbi function defined in Step 2.17. Set the eighteenth cell to:
viterbi_lattice, backpointer_matrix = viterbi(USE_OBS, unique_elems, I, A, B)
- Note that this step can take several minutes to run.
Step 2.19 - CELL 19: Utility Function to Read Best Path
We can read the best (i.e. highest probability) path using the backpointer matrix generated in Step 2.18. The nineteenth cell defines a utility function to read out the highest probability path from the Viterbi lattice. Set the nineteenth cell to:
### CELL 19: Utility method to read out best path from Viterbi lattice and backpointer matrix ###
def read_best_path(OBS, unique_elems, viterbi_lattice, backpointer_matrix):
elements = []
# Get musical elements for observations in range 1 through len(OBS) starting from the back.
for t in range(len(OBS) - 1, 0, -1):
max = 0
argmax = 0
for s in range(viterbi_lattice.shape[0]):
val = viterbi_lattice[s][t]
if val > max:
max = val
argmax = s
elem_key = backpointer_matrix[argmax][t]
elem = unique_elems[elem_key]
elements.append(elem)
# Get state for first observation.
max_start = 0
argmax_start = 0
for s in range(viterbi_lattice.shape[0]):
val = viterbi_lattice[s][0]
if val > max_start:
max_start = val
argmax_start = s
start_elem = unique_elems[argmax_start]
elements.append(start_elem)
elements.reverse()
return elements
Step 2.20 - CELL 20: Reading Best Path
The twentieth cell runs the read_best_path function defined in Step 2.19. Set the twentieth cell to:
### CELL 20: Reading best path
elements = read_best_path(OBS, unique_elems, viterbi_lattice, backpointer_matrix)
Step 2.21 - CELL 21: Utility Function to Generate MIDI Stream from Generated Elements
Now that we have our predicted musical elements from Step 2.20, we can generate a MIDI stream from them using the music21 stream.Stream method. The first step is to iterate over each predicted element and to create an instance of the analogous music21 Rest, Note, or Chord object. These music21 objects are appended to the music list. The stream.Stream method is called on the music list to generate the MIDI output that we need. The twenty-first cell defines a utility function to generate the MIDI stream. Set the twenty-first cell to:
### CELL 21: Utility function to generate MIDI stream from generated musical elements ###
def generate_midi_stream(elements: list) -> Tuple[list, stream.Stream]:
music = []
for element in elements:
if element["name"] == "<REST>":
m = note.Rest()
m.duration.quarterLength = element["duration"]
if element["name"] == "<CHORD>":
m = chord.Chord(element["notes"])
m.duration.quarterLength = element["duration"]
if element["name"] == "<NOTE>":
m = note.Note(element["pitch"])
m.duration.quarterLength = element["duration"]
music.append(m)
midi_stream = stream.Stream(music)
return music, midi_stream
Step 2.22 - CELL 22: Generating MIDI Stream from Generated Elements
The twenty-second cell runs the generate_midi_stream from Step 2.21. Set the twenty-second cell to:
### CELL 22: Generating MIDI stream from generated musical elements ###
music, midi_stream = generate_midi_stream(elements)
-
If you print the returned
musiclist, you should see the following output:
[<music21.note.Rest 16th>, <music21.note.Rest 16th>, <music21.note.Note C>, <music21.chord.Chord E4 B-3>, <music21.note.Note B->, <music21.chord.Chord D2 E2>, <music21.note.Note F#>, <music21.note.Note G#>, <music21.note.Rest 217/100ql>, <music21.chord.Chord C2 B4>, <music21.note.Rest 52/25ql>, <music21.chord.Chord E5 A4>, <music21.note.Note G#>, <music21.note.Note D>, <music21.note.Note C>]
-
If you print the returned
midi_streamobject, you should see output similar to:
<music21.stream.Stream 0x2a5ec64d720>
Step 2.23 - CELL 23: Exporting MIDI Data
We can easily export our MIDI stream to a file using the music21 write method. The twenty-third cell exports the MIDI data. Set the twenty-third cell to:
### CELL 23: Writing MIDI data to disk ###
FILENAME = "hmm_music_exp_1_using_schubert_fantasie.mid"
midi_stream.write("midi", FILENAME)
-
Obviously, you can set
FILENAMEto whatever you would like. I opted to use the format:
hmm_music_exp_[EXPERIMENT NUMBER]_using_[DESCRIPTION OF INPUT DATA].mid
- This step completes building of the notebook.
Step 3
- With the notebook build completed, you can perform additional experiments by using the other observation sequences specified in Step 2.2. You need only update the
USE_OBSconstant to point to the sequence that you would like to use. - Remember to update the
FILENAMEconstant in Step 2.23, assuming that you would like to save newly generated music to a different MIDI file.
Checking Your Output
I ran the same experiments (i.e. using the same 4 observation sequences) outlined in this Part 1 guide and I uploaded the results to Kaggle. You can access the experimental results via the Music Generation with GiantMIDI-Piano dataset, and specifically within the hmm_experiments folder. The hmm_experiments folder contains four sub-folders that include the results of the four experiments using a Hidden Markov Model (HMM) for music generation. Each sub-folder includes a:
-
Setup
.txtfile: This file details the MIDI scores used as input data for the HMM, along with the observation sequence used to generate the music sequence output. -
Output
.midMIDI file: This MIDI file is the MIDI representation of the generated music for the particular experiment. -
Output
.wavfile: This WAV file is the audio representation of the generated music for the particular experiment. A piano synthesizer was used to generate the audio outputs.
I will describe how you can listen to and interact with your generated MIDI files in the Part 2 guide. However, if you would like a preview, you can listen to the .wav files in the four experiment sub-folders. These .wav files were generated using a commercial piano synthesizer (i.e. a synthesizer that I own). Your experimental results should be exactly the same, assuming you followed the guide as written.
Conclusion and Next Steps
Congratulations on completing this Part 1 guide. In the Part 2 guide, you will use Signal Online MIDI Editor to listen to and interact with your generated music. Please do a search on my HackerNoon username to find the Part 2 guide. See you in Part 2!