

Authors:
(1) Keivan Alizadeh;
(2) Iman Mirzadeh, Major Contribution;
(3) Dmitry Belenko, Major Contribution;
(4) S. Karen Khatamifard;
(5) Minsik Cho;
(6) Carlo C Del Mundo;
(7) Mohammad Rastegari;
(8) Mehrdad Farajtabar.
Table of Links
2. Flash Memory & LLM Inference and 2.1 Bandwidth and Energy Constraints
3.2 Improving Transfer Throughput with Increased Chunk Sizes
3.3 Optimized Data Management in DRAM
4.1 Results for OPT 6.7B Model
4.2 Results for Falcon 7B Model
6 Conclusion and Discussion, Acknowledgements and References
3.1 Reducing Data Transfer
Our methodology leverages the inherent activation sparsity found in Feed-Forward Network (FFN) models, as documented in preceding research. The OPT 6.7B model, for instance, exhibits a notable 97% sparsity within its FFN layer. Similarly, the Falcon 7B model has been adapted through finetuning, which involves swapping their activation functions to ReLU, resulting in 95% sparsity while being almost similar in accuracy (Mirzadeh et al., 2023). In light of this information, our approach involves the iterative transfer of only the essential, non-sparse data from flash memory to DRAM for processing during inference.
While we employ the 7B models as practical examples to elucidate our approach, our findings are adaptable, and they can be extrapolated to both larger and smaller scale models.
Selective Persistence Strategy. We opt to retain the embeddings and matrices within the attention mechanism of the transformer constantly in RAM. For the Feed-Forward Network (FFN) portions, only the non-sparse segments are dynamically loaded into DRAM as needed. Storing attention weights, which constitute approximately one-third of the model’s size, in memory, allows for more efficient computation and quicker access, thereby enhancing inference performance without the need for full model loading.
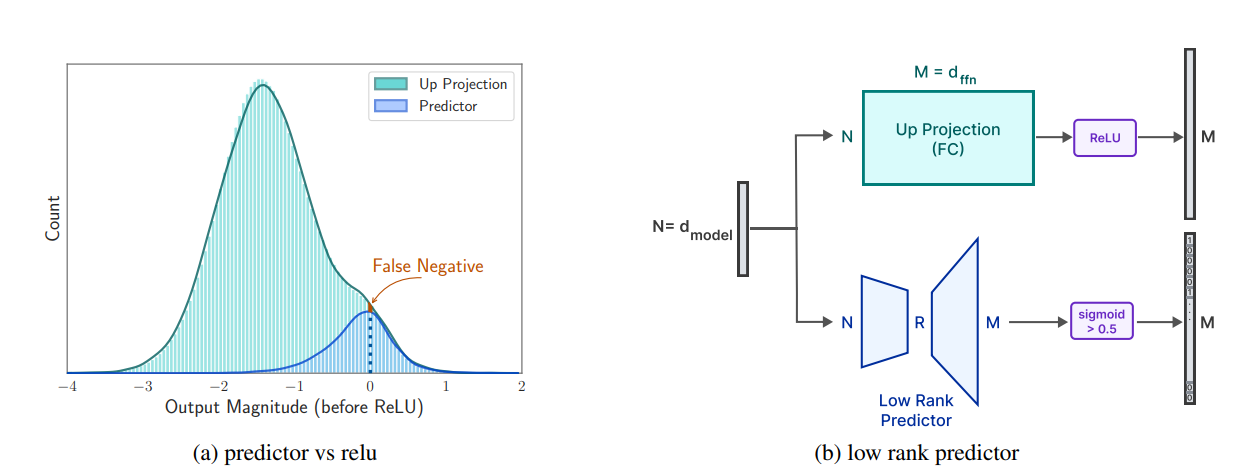
Anticipating ReLU Sparsity. The ReLU activation function naturally induces over 90% sparsity in the FFN’s intermediate outputs, which reduces the memory footprint for subsequent layers that utilize these sparse outputs. However, the preceding layer, namely the up project for OPT and Falcon, must be fully present in memory. To avoid loading the entire up projection matrix, we follow Liu et al. (2023b), and employ a low-rank predictor to identify the elements zeroed by ReLU (see Figure 3b). In contrast to their work, our predictor needs only the output of the current layer’s attention module, and not the previous layer’s FFN module. We have observed that postponing the prediction to current layer is sufficient for hardware aware weight loading algorithm design, but leads to more accurate
outcome due to deferred inputs. We thereby only load elements indicated by the predictor.
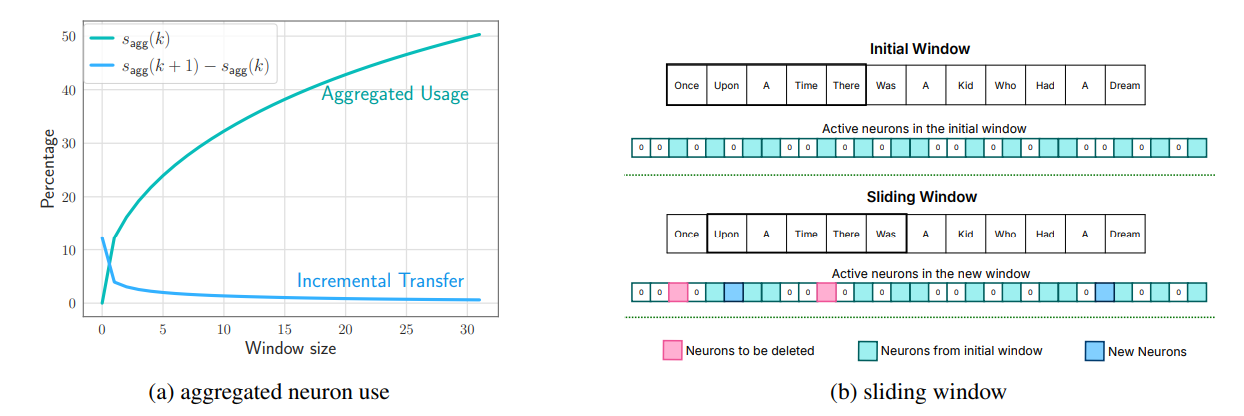
Neuron Data Management via Sliding Window Technique. In our study, we define an active neuron as one that yields a positive output in our low rank predictor model. Our approach focuses on managing neuron data by employing a Sliding Window Technique. This technique entails maintaining a DRAM cache of of only the weight rows that were predicted to be required by the the recent subset of input tokens. The key aspect of this technique is the incremental loading of neuron data that differs between the current input token and its immediate predecessors. This strategy allows for efficient memory utilization, as it frees up memory resources previously allocated to cached weights required by tokens that are no longer within the sliding window (as depicted in Figure 4b).

This paper is available on arxiv under CC BY-SA 4.0 DEED license.