

Generative AI systems are AI systems capable of multimodal processing, content creation, and decision-making. They are equipped with data sources and specialized tools, communicating within the system through a module for information retrieval and storage.
The current stage of Generative AI is good at content creation and audio and visual analysis (e.g. GPT4v). Generative AI systems make LLMs multimodal (texts, audio, video, vision), combining and generating different data types. The rise of Generative Multimodal Models brings up a new perspective of thinking of AI as a system rather than Large Language Models (LLMs) alone.
Generative AI systems are built in blocks, each performing a distinct function and interacting with other blocks to achieve a larger goal. The systems are equipped with external data sources and tools (e.g., calculators and databases) with LLMs as the interface for providing reliable answers.
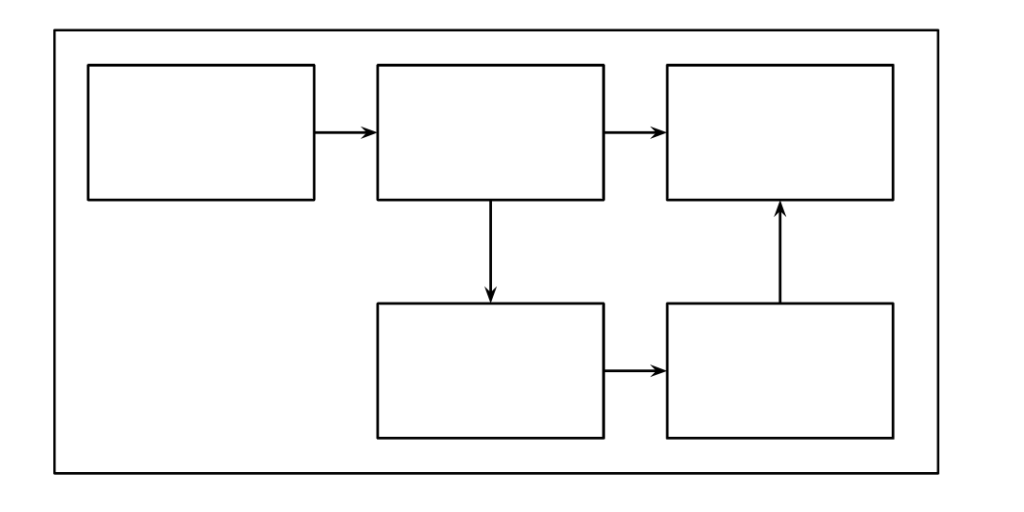
Composition of Generative AI Systems
Generative AI Systems work by combining multiple blocks with different functionalities. It uses a divide-combine-conquer strategy in which different blocks perform different tasks and then combine the needed results from each block to form a uniform output. The goal of the system must be defined.
When building a generative AI system architecture, the following should be considered:
Refinement: Refinement plays a huge role in Generative AI as it helps with the reliability, accuracy, and performance of LLMs. A Generative AI system should be able to take the results, compare them to the real world, and take them in as data to build a more accurate and foolproof AI. This involves fine-tuning language models, Data Augmentation, and Transfer Learning. These collectively enhance LLMs' efficiency, accuracy, and scalability, making them more robust and capable of handling diverse and complex tasks.
Enhancement: This is the augmentation of the system with external data sources and tools (e.g., databases and calculators) to build a more reliable and accurate system. This enables the LLM to have more accurate and updated information when generating responses and new content. This solidifies the authenticity of the content generated and also enables the LLMs to achieve reasoning capabilities through the integration of external tools.
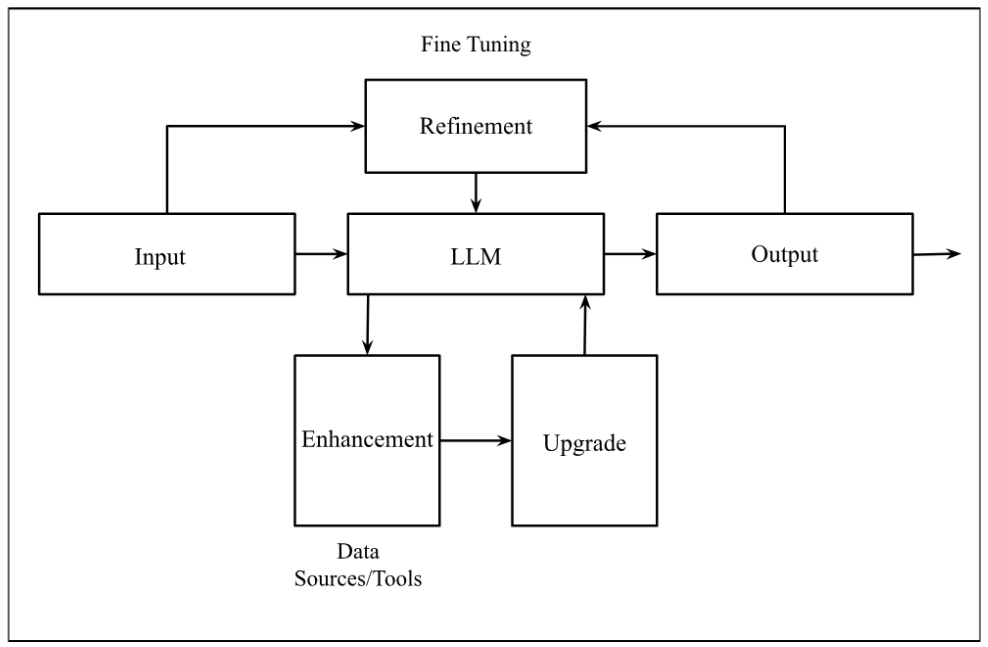
Building a Generative AI System
Generative AI systems are made of blocks, each with a different functionality. Imagining LLMs as a system helps understand their building blocks and helps design them for specific applications. Large Language Models can be extended by enhancing their functionalities (external data sources) to return a specific task output.
Multimodal models do this by processing multiple data types such as texts, images, video, and audio to perform specific outputs that require the distribution and combination of different output models using fusion techniques and cross-attention.
Example Architecture
Text.input → text encoder
Image.input → image encoder
Audio.input → audio encoder
↓
Cross-attention mechanism
↓
Multimodal fusion layer
↓
Output layer
When data (text, audio, video, images) is entered into the system, they are encoded to what can be understood by the system (embedding). The data will be fed into the generative AI models (LLMs), which will make a retrieval request to the given tools and or databases to get updated data and capabilities, then return to the generative AI to generate new content, which will be output.
With the rise of agent AI every day, new generative AI systems are built to carry out specific tasks and automation. This will lead to more productivity, especially in jobs like programming, marketing, manufacturing, Legal, and Healthcare.
References
https://arxiv.org/pdf/2407.11001
https://ai.meta.com/tools/system-cards/multimodal-generative-ai-systems