

As digital architects, we have a crucial duty to create and safeguard a landscape where security is essential. Security isn't just about technology; it's about ethics too, protecting not just information but the very core of our digital society. Prioritizing security in our microservices architecture isn't just about preventing breaches but about cultivating a culture of respect for privacy, integrity, and resilience.
In a world where a single vulnerability can have far-reaching consequences, our unwavering focus on security is an act of stewardship, ensuring that the digital ecosystems we create are robust, efficient, trustworthy, and sustainable. Each action we undertake to implement security features is a stride toward building a safer, more reliable digital future for all.
As a Senior Software Engineer with over 13 years of experience, these are my personal go-to best practices when designing an AWS service. This is not an exhaustive list, given that security cannot be achieved by following a checklist.
1. Use Customer Managed Key for KMS instead of the default key
Key Rotation Control
Using the same key for encrypting data for long periods of time can provide the bad actors with a corpus of data where subtle patterns can surface. This is a possible security risk, depending on the severity of your application. You can rotate your keys manually or on a fixed schedule. The duration of rotation can be annual, just like the default key, or a much more frequent cadence. There is a charge for key rotations, so the rotation duration should be chosen carefully.
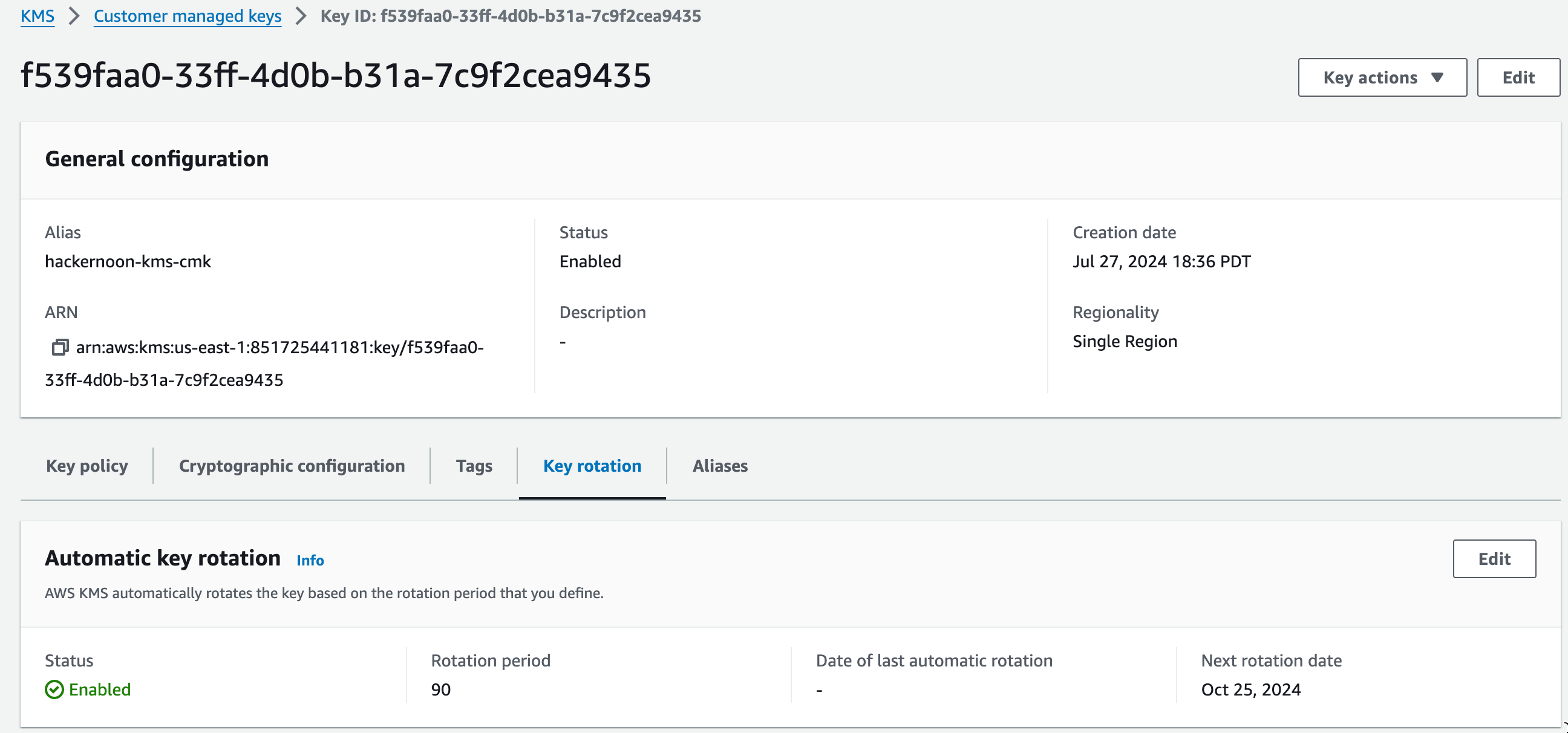
Bring your Own Key
AWS KMS allows you to bring your own key, which can provide much more fine-grained control over the lifecycle of creation and the entire lifecycle of the key. This can be beneficial if your organization has policies of centrally managing encryption keys.
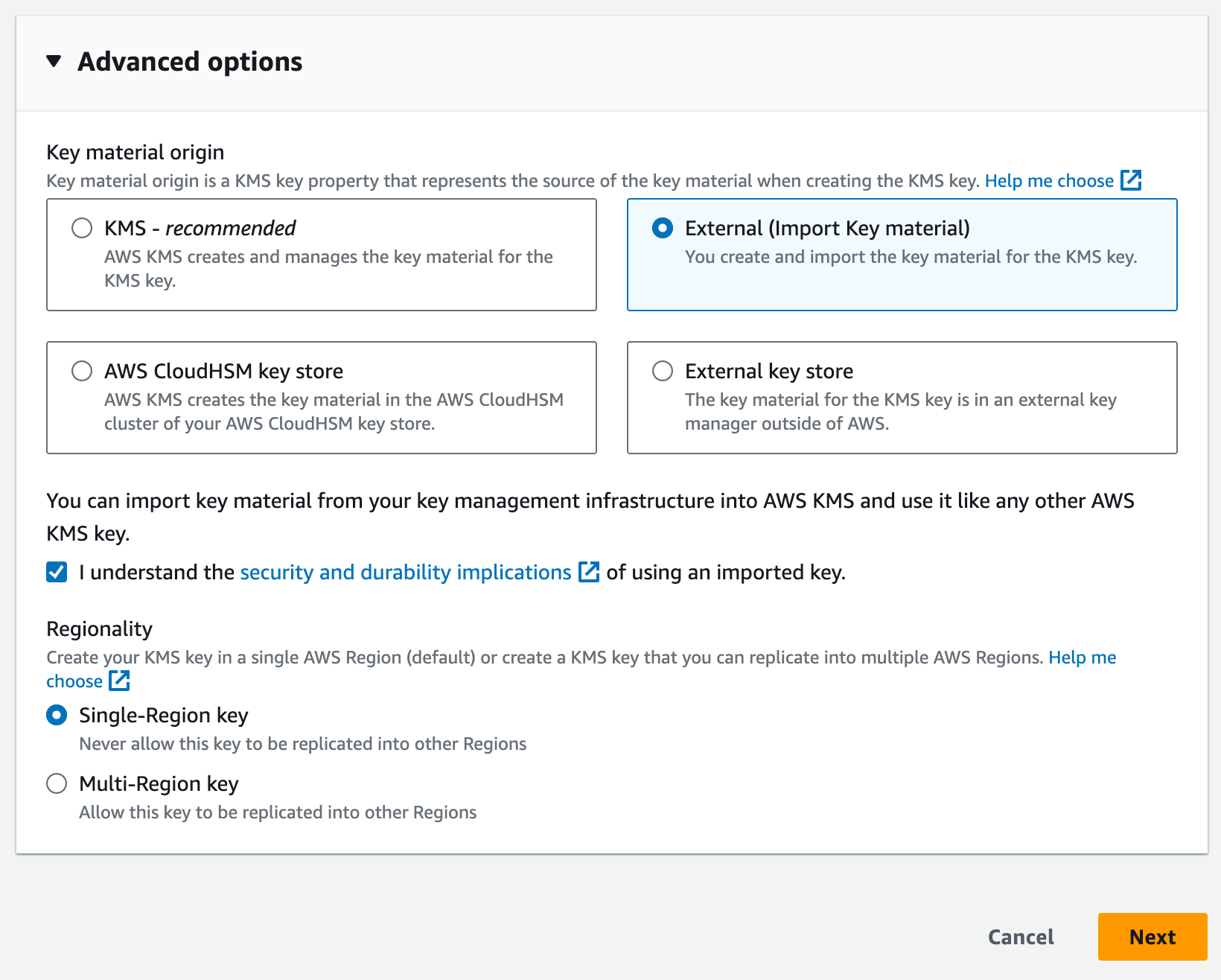
Cross Account Sharing
The AWS Managed Key for your AWS account cannot be shared across different AWS accounts. This can be a bummer since a large organization can have hundreds of AWS accounts for each of its services, and there are instances when two services need to communicate. AWS KMS CMK can be shared across AWS accounts, providing more flexibility over the security of your services
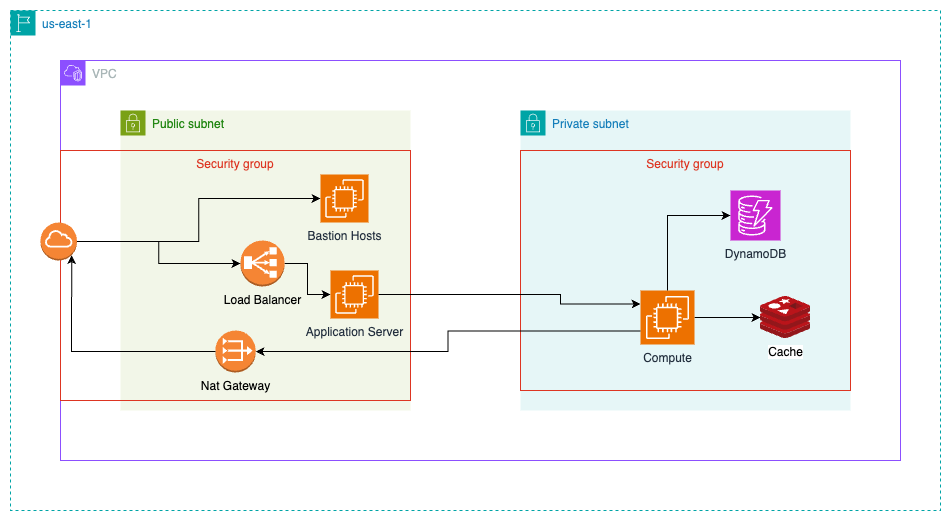
2.Use VPCs and Subnets decisively
VPCs and Subnets
I want to emphasize the importance of understanding Virtual Private Cloud (VPC) in AWS. A VPC is like having my own private slice of the AWS cloud. I have complete control over my virtual networking environment within the VPC. I can segment the VPC's IP address range into subnets to effectively manage network traffic and keep resources isolated. With VPC, I can ensure security by isolating my network from the internet and other AWS customers. This means I have full control over routing and access control within my VPC.
There are two kinds of subnets.
- Public Subnets: Directly accessible from the internet and typically used for resources that need to communicate directly with the internet, such as web servers, load balancers, and bastion hosts
- Private Subnets are not directly accessible from the Internet and are used for resources that should not be directly exposed to the Internet, such as databases, application servers, and caches.
Connecting VPC to the Internet
We need to attach an Internet Gateway to your VPC to allow resources in your VPC to communicate with the Internet. Once attached, we need to update the route table to direct internet-bound traffic to the Internet Gateway.
NAT Gateway and Public Subnet Connectivity
It's important to understand how it works to ensure that instances in private subnets can securely connect to the Internet and other AWS services. This setup effectively shields the instances from unsolicited inbound connections while allowing them to initiate outbound connections.
Keeping them separate is primarily about
- Security: Isolating sensitive resources in private subnets reduces the attack surface.
- Control: Managing access control and firewall rules is more accessible when resources are logically grouped.
Compliance: Many compliance standards require specific data or services to be isolated from direct internet access.
3. Principle of Least Privilege
It is highly recommended that you use an IAM Role instead of an IAM User. The Principle of Least Privilege is a fundamental security concept that advocates granting only the minimum permissions necessary to perform required tasks. In AWS, this principle can be effectively implemented using IAM Role Permissions and Permission Boundaries.
Separate Role per AWS Resource
I make sure to remember this important piece of information: When working with AWS, it's essential to establish distinct IAM (Identity and Access Management) roles for individual AWS resources or services that my application interacts with. This practice is crucial for adhering to the principle of least privilege. By creating separate IAM roles, I enhance security isolation, simplify auditing and management processes, and minimize the potential impact in the event of a security breach.
- Identification—Find all the AWS resources for your service. If the application is deployed using CloudFormation, the CloudFormation stack will list all the relevant services. If it’s a legacy service, it's important to implement separate roles for important resources, namely S3 buckets, Database services like DynamoDB, and compute resources like EC2 and Lambda.
- Creation of Role - For each resource, create a separate IAM Role. If you have 3 Lambdas performing different tasks, have 3 separate IAM Roles.
- Permissions - Only assign the permissions that are needed to the associated resource to function
Granular Role Definition
When I assign IAM roles, it's important for me to carefully assess the required permissions for each specific resource to effectively carry out its tasks. This involves granting the minimum necessary permissions using the ALLOW effect, which specifies the actions a resource is permitted to perform. In some cases, I can judiciously apply the DENY effect to explicitly restrict certain actions, effectively overriding any conflicting ALLOW permissions. Using DENY can help me prevent accidental inclusion of unwanted permissions, ensuring that access is strictly controlled.
While it might look like a lot of work ahead of time, there are certain advantages
- Reduces risk of misuse and unauthorized access
- Streamlines compliance and security audits. A 1:1 relationship can be understood much more easily by external individuals who have little knowledge of your service
- You can skip adding explicit documentation as your IAM Role Permission itself is a single source of truth, defined specifically and clearly.
Use Permission Boundry
While permission statements specify the action and Effect, by default, they allow those actions to be performed on all the resources. If I want a Lambda to be able to read an S3 bucket, in the associated IAM Role permission statement, I add Effect ALLOW and add the necessary Actions. This still allows me to read data from all the buckets. This might not be ideal, and I might want this specific Lambda function to only be able to read from specific buckets.
Additionally, we can use permission boundaries with fine-grained permission. For an IAM Role, we can have a first policy statement that allows a lambda to read from a bunch of S3 buckets, and the second policy statement allows a lambda to both read and write from another set of S3 buckets.
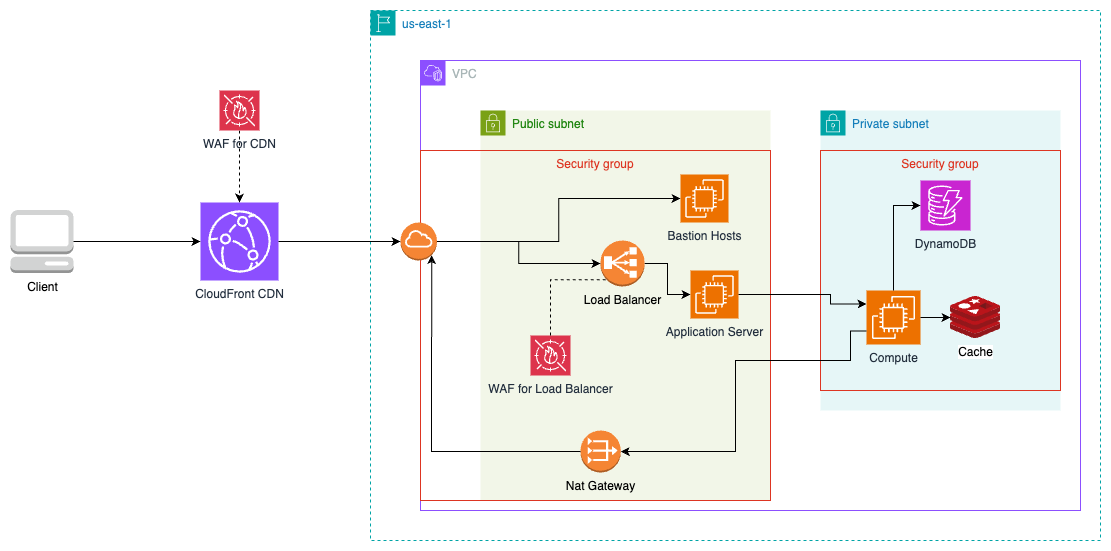
4. Use AWS WAF
There are a lot of common exploits out in the wild to which our service can be susceptible. Not only do we have to deal with bad actors, but many of them can just be script kiddies running tools that try to discover well-known issues like SQL Injection, XSS attacks, and Log4J vulnerability, to name a few. Thankfully AWS provides a service known as Web Application Firewall with a set of default rules so that we, as service owners, can focus on building the most user-friendly product.
We can also create simple Rate-Limiting rules to prevent Distributed denial-of-service attacks. We can choose total rate limiting, per IP rate limiting, or both.
AWS WAF can be integrated at the edge using CloudFront as the CDN provider or attached to the Load Balancer sitting inside the AWS Account, which itself can be inside a Public Subnet. This acts as the last line of defense before the web requests are received by the web server.
5. Have an Incident Response Plan
As someone who's been in the trenches for years, I can't stress enough how crucial it is to have an incident response plan. I've seen the chaos that ensues when a security breach hits, and there's no plan or a half-baked plan in place. It's like trying to extinguish a fire by passing along buckets of water – frantic, ineffective, and ultimately disastrous. That's why I always insist on having a solid incident response plan, no matter the product size or the perceived risk level. We, as humans, are terrible at analyzing risk. Thus, a plan is our best course of action in such situations.
I remember the Log4J vulnerability being out in the wild. We were throwing everything against the wall and hoping it would work. The network infrastructure is multi-layered, and blocking such injection attacks comes at the cost of performance. We had to implement different levels of stopping to varying layers of the infrastructure stack.
Having a plan for responding to incidents isn't only about preparing for the worst; it's also about having peace of mind. When I go to sleep at night, I rest easier, knowing that we have a set of steps to follow if something goes wrong. It's similar to having a plan for escaping a fire in your home – you hope you'll never have to use it, but just having it in place makes you feel more secure. When an incident happens under pressure, having a plan allows me to think clearly and act decisively. It's not just about safeguarding data or systems; it's about safeguarding people – their livelihoods, stress levels, and, ultimately, their well-being. This is why I will always advocate for the importance of incident response planning in cybersecurity.
The Incident Response Plan doesn’t need to be expansive like a contractual agreement between two corporations. It should be a game plan to ensure everyone knows their role and can play their part effectively.
Incident Response Team
- Incident Leader - leads the team, makes judgment calls, and is the threaded owner for the incident.
- Oncalls for affected service - The leader will invite or require the affected service on calls to be present in the situation room (physical or virtual)
- Product Owner or Technical Lead - To keep the respective owners in the loop
- Legal - if customer data is affected, then legal can provide valuable advice.
Incident Classification
There should be clearly defined criteria to establish the severity of the incident. A good idea is to have levels from 1 to 4, where 1 is a minor incident and 4 is the most critical. Some organizations might flip the numbering. No matter what classification you use, make sure everyone understands the incident classification. The Incident Leader should be responsible for determining the classification and should have the flexibility to change it based on new information presented to them.
Response Steps
- Identify the incident—Determine the possible incident. This can be done by on-call engineers, the security team, or any employee. Every organization should have a policy and methodology for any employee to contact the central team that handles any kind of incident, whether digital or physical.
- Mitigation—Before the issue is fixed, the first order of business should be to mitigate the immediate risk. If the cryptographic key is being leaked, rotate the keys manually. If the data is still being uploaded, try to block the data transfer out of your network. If customer login session tokens are leaked, identify those customers and invalidate those tokens. This might ask the affected customers to log in again, but it is a short-term fix for an immediate problem.
- Containment—Once the incident’s effect has been mitigated, it's time to temporarily add safeguards to ensure that the bad attackers do not try again. If you are defending a fort and you manage to neutralize the soldiers who made it over the moat, you do not return to normal. You remain in a heightened state of awareness for some time and increase the patrols.
- Recovery—If some fixes had to be implemented but were too risky and intrusive during mitigation, this would be the time. They could be as simple as proactive security updates or server kernel updates. If data was destroyed, we would need to restore it from backups.
- External Communication - During the entire process, the individuals working on the incident should keep notes so that there is a clear picture of the issue and people outside of the incident response team can have a better context. This can be useful for the public relations team when drafting public announcements.
- Retrospectives - This is not urgent and should be conducted once the incident is behind us. This is the time to reflect on actions and take lessons. The culture should be blameless, and focus should be placed on having proper guardrails to ensure no employee is able to create a vulnerability by mistake. The retrospective might yield action items that are assigned to various teams or individuals. Each of them should be time-bound, and the senior leadership should try to enforce the proposed fixes.
I want to emphasize that while this template provides a solid foundation, it's not an exhaustive list. In my experience, I've learned that each organization faces unique challenges, and no two incidents are exactly alike. This plan is a starting point, a framework to build upon. The cybersecurity landscape is constantly evolving, and so should your plan. I encourage you to view this template as a living document, one that grows and adapts to your organization's needs and the ever-changing threat landscape. Remember, the goal isn't to create a perfect plan – it's to be better prepared today than you were yesterday. Stay vigilant, keep learning, and never stop improving your defenses.