

How Does a Linked List Work?
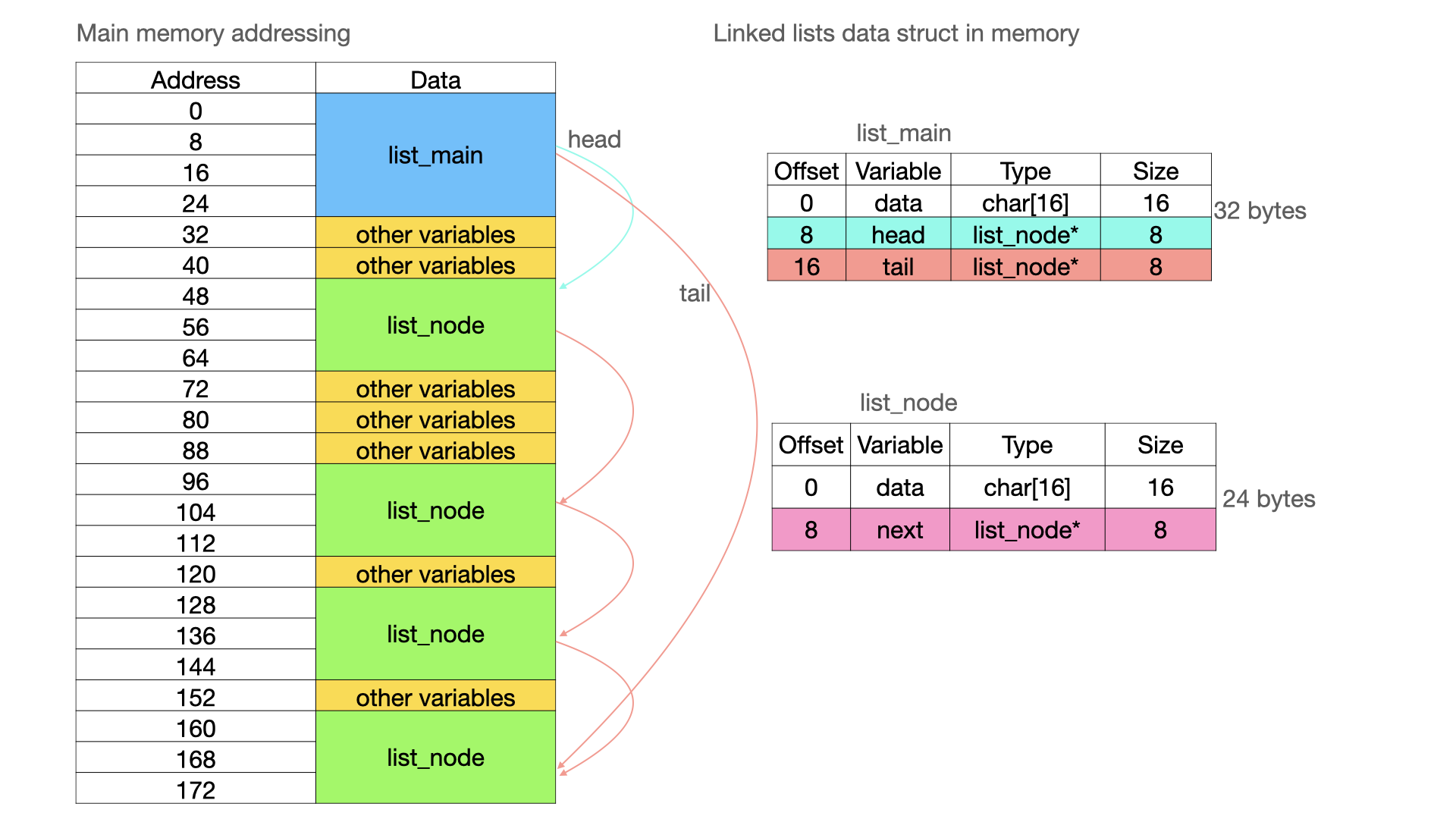
A linked list is a data structure where the fields of each data are connected by pointers instead of offsets. It consists of a main element that stores the first and last elements, so-called node elements, containing all necessary user fields (such as a phone, owner, company, etc.) and a pointer to the next node. The last element is linked to the NULL field which indicates the end of the list.
When a new element is added to the linked list, the main node must update the “tail” pointer to the new end-node, and the previous NULL-pointer must be updated to the new tail.
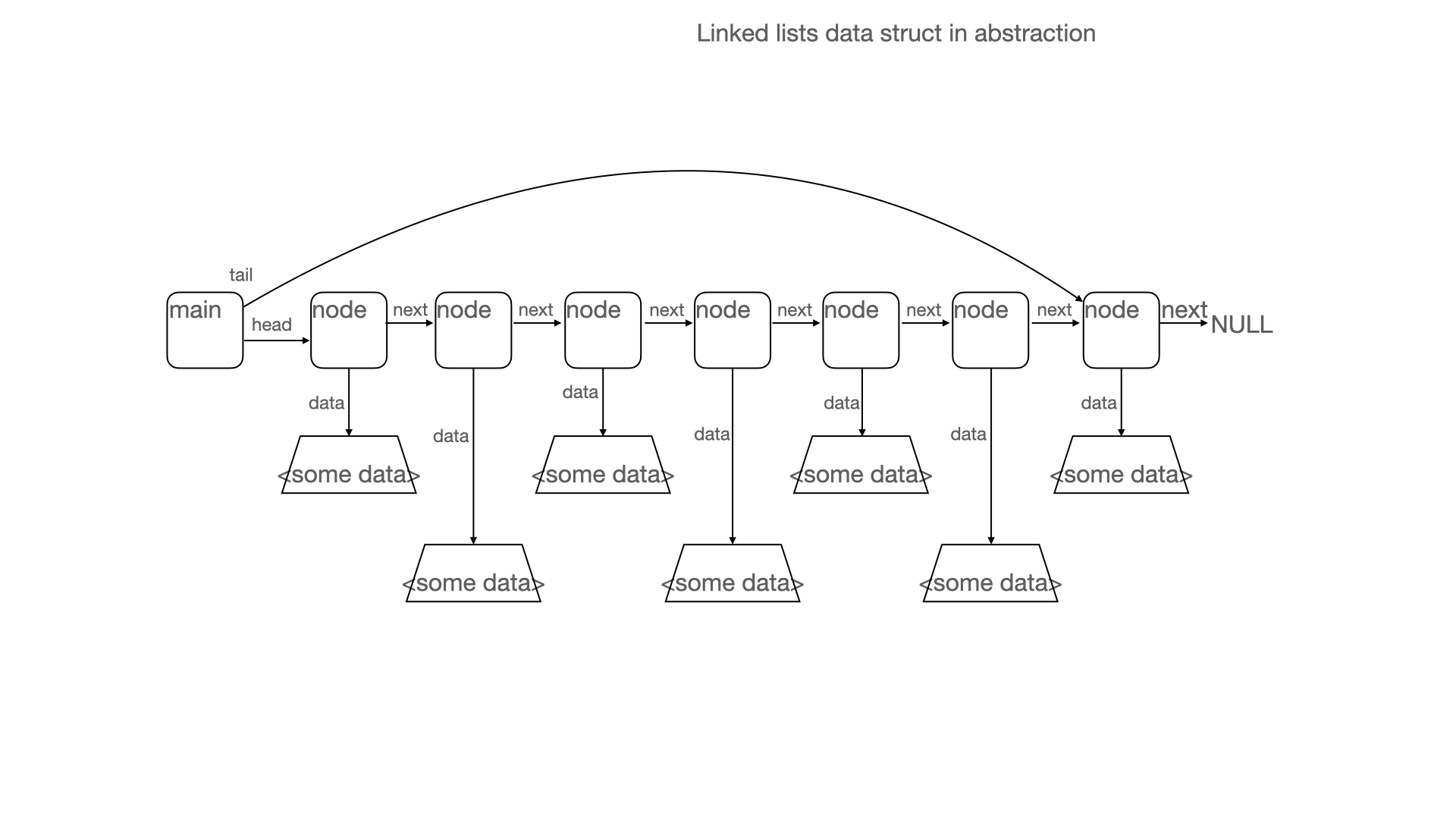
This data structure allows an efficient recording of new data without resizing the entire array. It's an effective method for storing write-only data, and it doesn’t require knowing the amount of elements in advance. It is a simple data structure, and in memory, it looks like this:
Linked List for Eviction Keys
In an earlier article, we discussed the need for a buffer to scan the tree without leaving the tree after each item deletion. In languages with GC, this isn’t a problem. However, when the application code manages memory, a buffer based on a linked list containing outdated elements can be a solution.
A linked list allows fast addition of elements. However, finding anything in the linked list requires sequential scanning, making it unsuitable for quick key retrieval. Thus, it’s an efficient solution for logging data, creating temporary buffers, and organizing data to make sequential reads from head nodes.
Finding elements to preempt is an example of such a task. Preemption is often used in the different cache implementations. The cache contains data that can be restored from other memory sources with larger latency. Cache is usually stored in the main memory. The main memory is limited, and for effective use, only a small snapshot of data can be stored in the main memory.
It requires us to use memory more smartly, avoiding memory usage for rarely requested data and removing such data if it becomes too infrequently requested.
An effective method for evicting fields in cache is the Least recently used (LRU) method. Here is the LRU representation below:
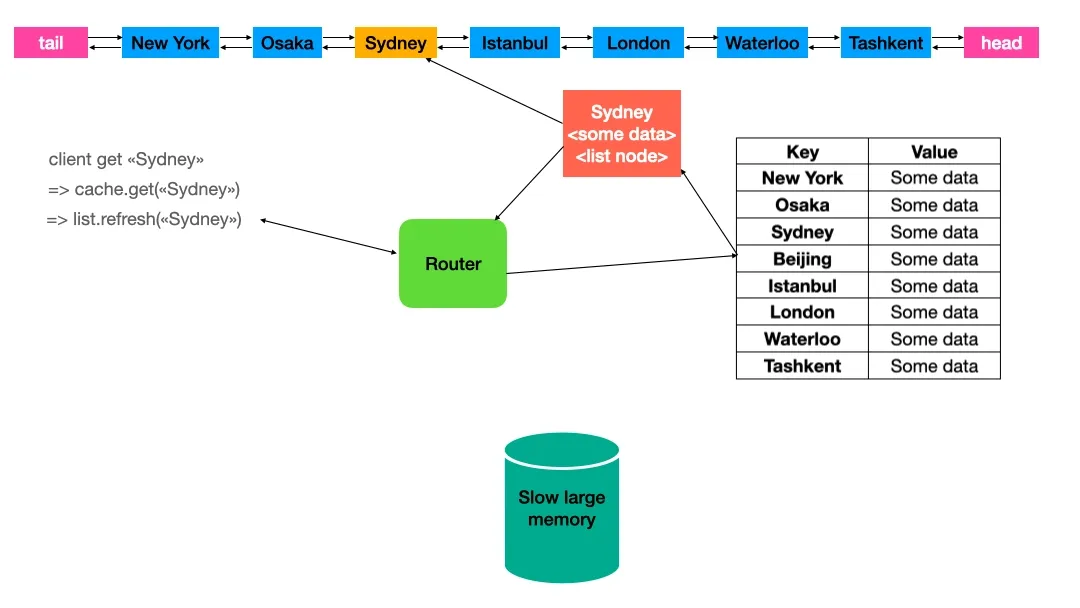
In this case, the application includes at least one linked list to store recently used objects and has other data structures (like a hash table) for a fast search. The nodes are interconnected.
When a user retrieves data from the hash table, the linked list refreshes this data by moving it to the tail. As a result, after several operations, the tail contains recently used data, while the head holds rarely requested data.
In cases of memory overflow, the application can scan the first N elements to release sufficient memory. This is a simple operation as the linked list adapts to sequential scans. Memory with rarely used data will be released, and new more frequent nodes can be stored in cache.
#include <stdlib.h>
#include <stdio.h>
typedef struct lnode_t {
struct lnode_t *next;
struct lnode_t *prev;
void *ptr;
} lnode_t;
typedef struct list_t {
lnode_t *head;
lnode_t *tail;
} list_t;
lnode_t* lru_insert(list_t *list, char *ptr) {
if (!list->head) {
list->head = list->tail = calloc(1, sizeof(lnode_t));
list->head->ptr = ptr;
return list->head;
}
lnode_t *saved_tail = list->tail;
lnode_t *new = calloc(1, sizeof(sizeof(lnode_t)));
new->ptr = ptr;
saved_tail->next = new;
new->prev = saved_tail;
list->tail = new;
return new;
}
void lru_update(list_t *list, lnode_t *lnode) {
if (list->tail == lnode) {
return;
}
lnode_t *saved_tail = list->tail;
saved_tail->next = lnode;
if (!lnode->prev)
list->head = lnode->next;
lnode->next = NULL;
lnode->prev = saved_tail;
list->tail = lnode;
}
void lru_evict(list_t *list, int items, void (*func)(void* arg, void *ptr), void* arg) {
lnode_t *lnode = list->head;
while(items-- && lnode) {
func(arg, lnode->ptr);
lnode_t *prev = lnode->prev;
lnode_t *next = lnode->next;
if (prev)
prev->next = next;
if (next)
next->prev = prev;
free(lnode);
lnode = next;
}
if (!lnode)
list->head = list->tail = NULL;
}
void print_deleted_obj(void *arg, void *ptr) {
printf("evicted: %p\n", ptr);
deleteThisInTheOtherStructure(arg, ptr);
}
int main() {
list_t *list = calloc(1, sizeof(list_t));
lnode_t *test = lru_insert(list, "some data");
lru_insert(list, "another data");
lru_update(list, test);
lru_evict(list, 1, print_deleted_obj, otherStructure);
}
One remark: when the number of using elements differs significantly in frequency (for instance, the 95% of requests distributed on the top 100 keys out of 1 million), the Splay Tree might be more suitable to store cache. This tree is balanced based on the frequency of each node usage.
The main idea of the Splay Tree is the opposite of LRU - the most used elements are located near the root, making this data structure ideal as a primary structure for the cache.
Eviction can be solved in two ways: by using a linked list interconnected with the main struct, or by modifying a Splay Tree to Threaded Binary Tree. The nodes in the Splay Tree are already ordered by frequency of use. Although additional threading of tree leaves may require more CPU time, therefore, it can save memory.
To better comprehend the acceleration of recently used data in memory, you can explore an example of live VM migration on this link.
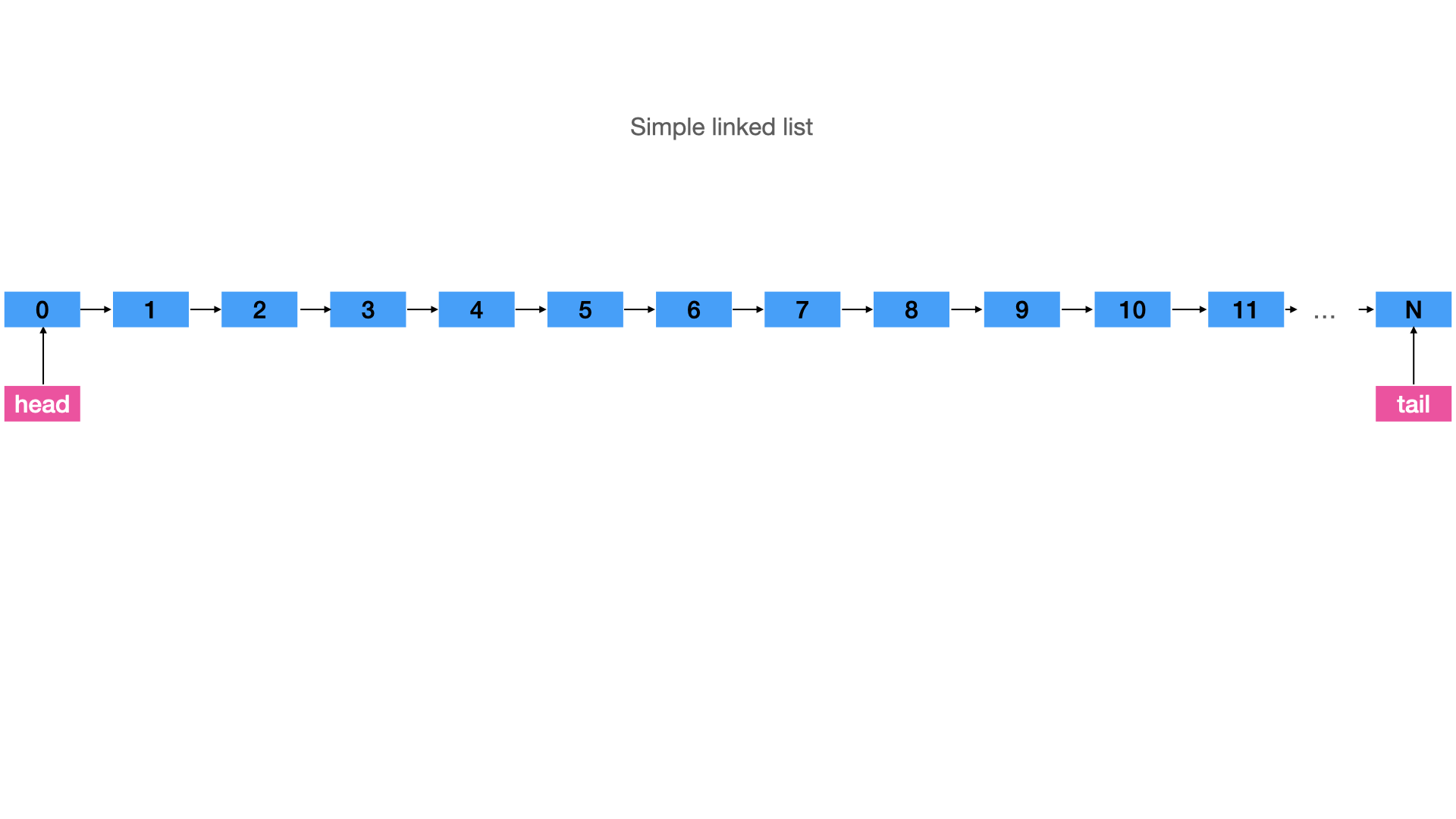
Improve the Scan Speed of the Linked List
As it was mentioned previously, linked lists offer the fastest solution for writing data. Their scanning speed is good, but it is slower than the scan speed in the array.
I described this problem as data locality in the previous article. However, as being similar to the binary trees, linked lists have a potential for improvements. Unrolling linked lists allows you to store more data in each node of the list. Thus, it saves memory on the next pointer node, and sometimes it improves performance, on condition that the size of the element fits in with the CPU cache line:

The main idea remains unchanged, but the representation of the list in the memory will be altered.
It will change in many ways. There are 2 options below:
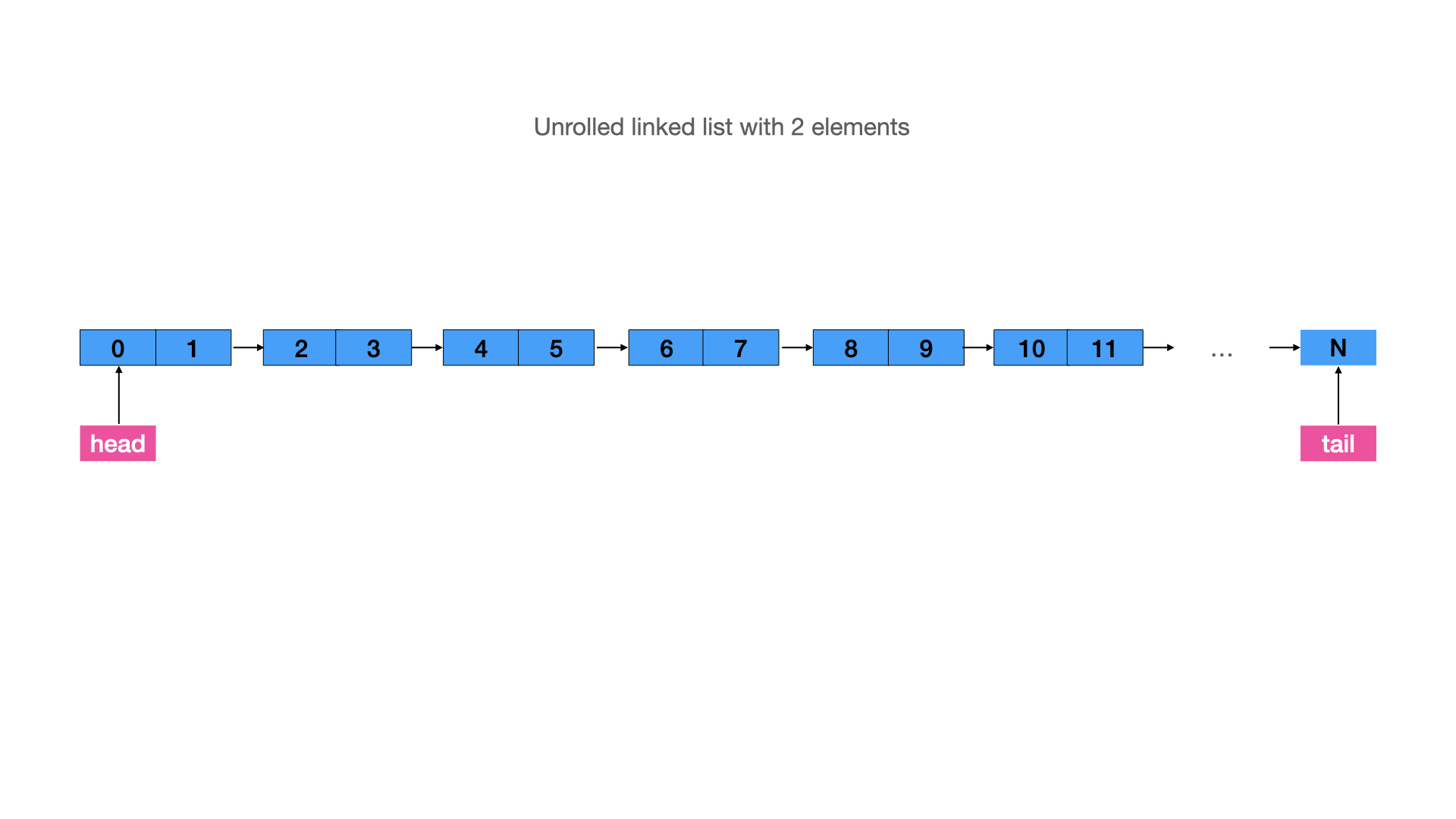
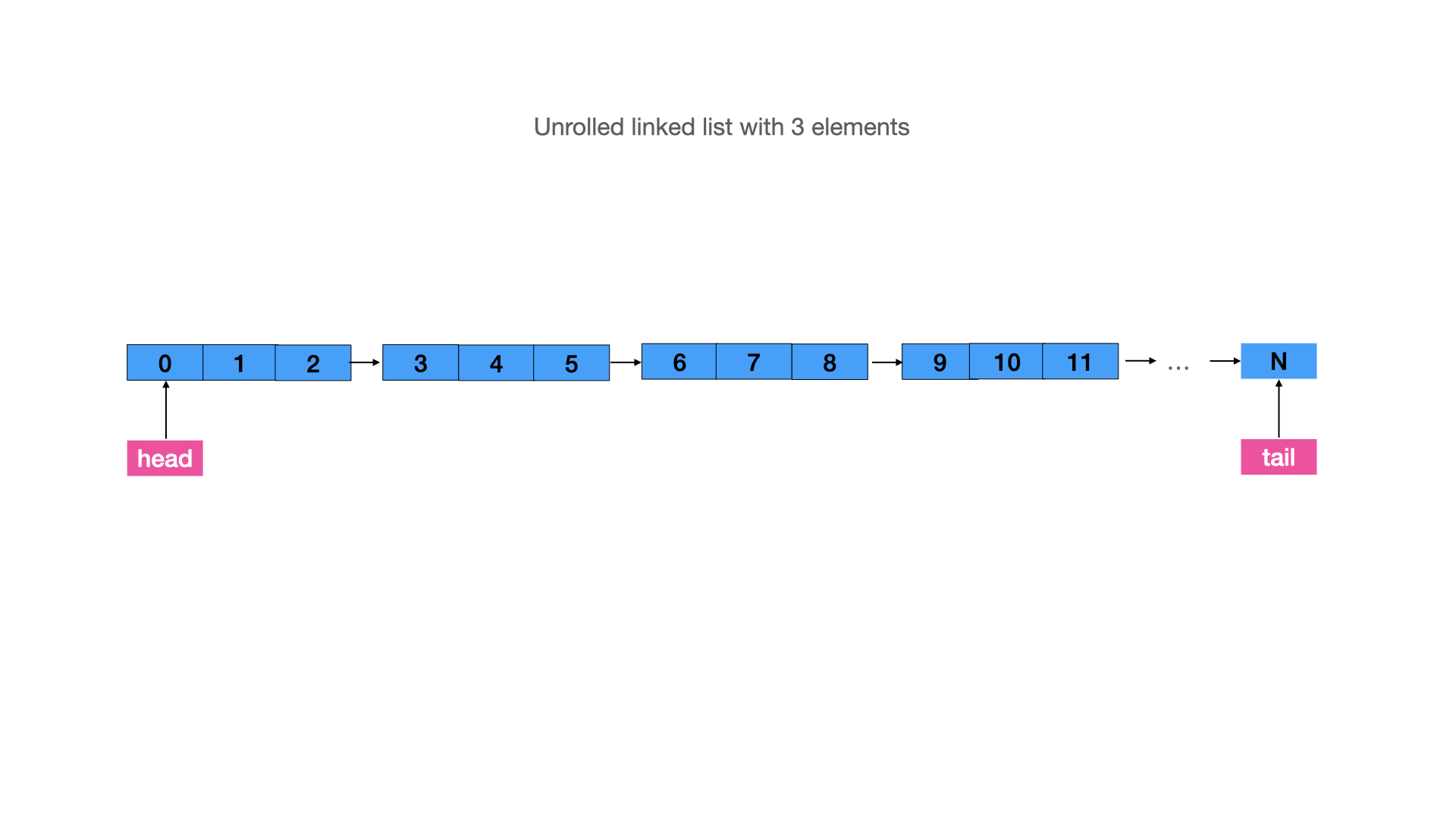
These improvements increase the performance of linked lists, but they add some complexity to the code. For disk-operations with a linked list, an unrolled node can have more elements. An easy way to understand how it works is to imagine a linked list of arrays.
In the code, we need to modify the struct description, and from now on, read or write each element in the array of the structure:
typedef struct lnode_t {
struct lnode_t *next;
struct lnode_t *prev;
void *ptr[3];
} lnode_t;
Skip List
The skip list is a method to improve the speed characteristics of search elements in a linked list. This type of linked list stores a key to order the linked list and includes extra pointers to locate nodes more efficiently than a simple scanning operation.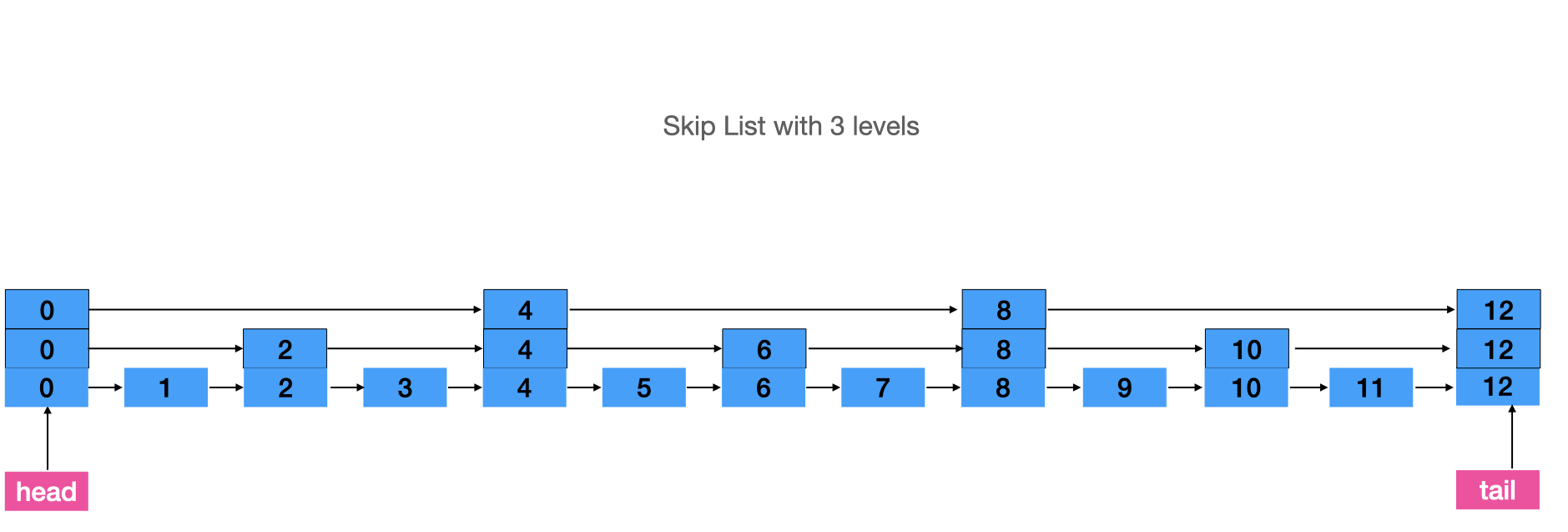
Extra nodes enhance the speed of traversing between nodes in a skip list. It works like a binary search. On the contrary, it takes more time to add new elements. Therefore, skip lists must have a key. Applications can make any number of levels to improve speed characteristics. In most cases, a better choice is to have slightly less or about the same levels as in height in the tree. (Watch the picture above)
While searching, an application starts from the highest level, which is the fastest route. Upon detecting the near key it descends to a lower level until the desired node is found.
This process results in a time complexity of O(log(n)). For instance, using 4 levels for a skip list with 16 nodes, 20 levels for 1 million nodes and 32 levels for 4 billion nodes provides similar time complexity to the RB-tree.
Skip list is better for the following reasons:
- Simplicity of implementation. Despite the similar characteristics to the RB-tree, it is much easier to implement and maintain.
- High efficiency in appending new nodes to the end of the skip list.
- Creating a thread-safe implementation of skip list is easier than the tree.
Let’s explore the implementation of this concept!
Structure nodes:
typedef struct skip_node {
uint64_t key;
uint64_t value;
struct skip_node **forward;
} skip_node;
typedef struct skip_t {
uint64_t level;
uint8_t max_level;
skip_node *header;
} skip_t;
Function to create nodes:
skip_node* create_skip_node(uint64_t key, int value, int level) {
skip_node *newskip_node = (skip_node*)malloc(sizeof(skip_node));
newskip_node->key = key;
newskip_node->value = value;
newskip_node->forward = malloc(sizeof(skip_node)*level);
for (uint64_t i = 0; i < level; i++) {
newskip_node->forward[i] = NULL;
}
return newskip_node;
}
skip_t* skip_new(uint8_t max_level) {
skip_t *list = (skip_t*)malloc(sizeof(skip_t));
list->level = 0;
list->max_level = max_level;
skip_node *header = create_skip_node(0, 0, max_level);
list->header = header;
for (uint64_t i = 0; i < max_level; i++) {
header->forward[i] = NULL;
}
return list;
}
During insertion, the task includes the detection of the correct location to store the node and determining the number of levels to connect to this node. The use of a random function for determining the levels helps simplify the process for each new node. On average, this function allocates the second level in 50% of cases, the third level in 25% of cases, and so on. This method minimizes the access time to the memory to rebalance elements.
uint64_t random_level(uint8_t max_level) {
uint64_t level = 1;
while (rand() < RAND_MAX / 2 && level < max_level) {
level++;
}
return level;
}
void skip_insert(skip_t *list, uint64_t key, int value) {
skip_node *update[list->max_level];
skip_node *current = list->header;
for (uint64_t i = list->level - 1; i >= 0; i--) {
while (current->forward[i] != NULL && current->forward[i]->key < key) {
current = current->forward[i];
}
update[i] = current;
}
current = current->forward[0];
if (current == NULL || current->key != key) {
uint64_t newLevel = random_level(list->max_level);
if (newLevel > list->level) {
for (uint64_t i = list->level; i < newLevel; i++) {
update[i] = list->header;
}
list->level = newLevel;
}
skip_node *newskip_node = create_skip_node(key, value, newLevel);
for (uint64_t i = 0; i < newLevel; i++) {
newskip_node->forward[i] = update[i]->forward[i];
update[i]->forward[i] = newskip_node;
}
}
}
Function to search nodes:
skip_node* skip_search(skip_t *list, uint64_t key) {
skip_node *current = list->header;
for (uint64_t i = list->level - 1; i >= 0; i--) {
while (current->forward[i] != NULL && current->forward[i]->key < key) {
current = current->forward[i];
}
}
current = current->forward[0];
++nodes_scan;
if (current != NULL && current->key == key)
return current;
else
return NULL;
}
A benchmark function to test the performance of a linked list, skip list, and the RB tree. The values, used as keys, are set as powers of two. The value for testing purposes doesn’t matter.
skip_t *skipList = skip_new(atoi(argv[1]));
list_t *llist = list_new();
tree_t *tree = calloc(1, sizeof(*tree));
size_t to_index = 50000000;
struct timespec s_icalc;
struct timespec e_icalc;
struct timespec s_scalc;
struct timespec e_scalc;
clock_gettime(CLOCK_REALTIME, &s_icalc);
for (uint64_t i = 0; i < to_index; ++i)
tree_insert(tree, i, i*2);
clock_gettime(CLOCK_REALTIME, &e_icalc);
count = 0;
nodes_scan = 0;
clock_gettime(CLOCK_REALTIME, &s_scalc);
for (uint64_t i = 0; i < to_index; ++i) {
node_t *node = tree_get(tree, i);
}
clock_gettime(CLOCK_REALTIME, &e_scalc);
clock_gettime(CLOCK_REALTIME, &s_icalc);
for (uint64_t i = 0; i < to_index; ++i)
skip_insert(skipList, i, i*2);
clock_gettime(CLOCK_REALTIME, &e_icalc);
count = 0;
clock_gettime(CLOCK_REALTIME, &s_scalc);
for (uint64_t i = 0; i < to_index; ++i) {
skip_node* ret = skip_search(skipList, i);
}
clock_gettime(CLOCK_REALTIME, &e_scalc);
clock_gettime(CLOCK_REALTIME, &s_icalc);
for (uint64_t i = 0; i < to_index; ++i)
list_add(llist, NULL, NULL);
clock_gettime(CLOCK_REALTIME, &e_icalc);
Results of testing this data structures on the sequentially growing keys:
|
structure/size |
insert |
search |
scanned nodes |
|---|---|---|---|
|
linked list |
1.234s |
∞ |
∞ |
|
RB tree, dynamical |
20.1s |
11.335s |
1248179373 |
|
skip list, 16 levels |
460.124s |
461.121s |
37584859275 |
|
skip list, 20 levels |
25.18s |
26.267s |
4230008370 |
|
skip list, 24 levels |
15.429s |
12.452s |
2548665327 |
|
skip list, 28 levels |
15.429s |
12.187s |
2516402553 |
|
skip list, 32 levels |
15.429s |
12.215s |
2516402553 |
This is the best time to insert (if you don't take into account a simple linked list) and a quite fast method to search elements.
Results of testing this data structures on the sequentially decreasing keys:
|
structure/size |
insert |
search |
scanned nodes |
|---|---|---|---|
|
linked list |
1.225s |
∞ |
∞ |
|
RB tree, dynamical |
22.314s |
13.215s |
1248179373 |
|
skip list, 16 levels |
9.429s |
482.073s |
39673590460 |
|
skip list, 20 levels |
10.429s |
30.295s |
4439292732 |
|
skip list, 24 levels |
10.429s |
15.156s |
2545126580 |
|
skip list, 28 levels |
10.141s |
16.1s |
2491915022 |
|
skip list, 32 levels |
10.193s |
15.1s |
2491915022 |
This is easy to understand: this implementation of a skip list only has a head pointer to the first element. Adding nodes to the end is more complex. To change this approach, we can add a second pointer (to the tail) or reverse skip list (the head will point to the big values). It means that a skip list is an effective data structure for log data such as Kafka streams. In that case, it can be at least twice as fast as the RB tree and easier to implement.
Skip List reduces the insertion speed of Linked list, however, for sequential data, it remains faster than other data structures with logarithm access time to the elements, especially while keys grow sequentially. Nevertheless, any sequential growth of the keys complicates insertions in the tree as it causes a lot of rotations to maintain the balance of the tree.
It works effectively only when the value is increasing(or decreasing) throughout the sequence. For instance, if we randomize the keys, the results will be different:
|
structure/size |
insert |
search |
scanned nodes |
|---|---|---|---|
|
RB tree, dynamical |
19.499s |
13.1s |
1255153312 |
|
skip list, 32 levels |
199.262s |
232.004s |
2569836454 |
As it’s seen, the distribution across the values doesn’t significantly impact the speed characteristic of the RB tree, but it notably affects the performance of the skip list.
Conclusions
Today, our applications might organize data in the memory or disk in different ways. Maps and lists play a significant role in arranging data in different orders for diverse purposes. These structures ensure sufficient performance, resource efficiency, and capability.
Occasionally, it’s not enough for our needs, and the application must be changed in the critical parts to be more optimal. Some cases may benefit from using more suitable data structures, such as trees for inexact matching or memory economy. Others - from improvements of the algorithm, such as using asynchronous methods to improve individual thread performance.
When all other options are exhausted there, the remaining approach is to adapt data structure and adjust methodology of use. There are examples of some changes in data structure to make these more suitable for a practically specific task.
While a linked list is primarily a write-only and sequence-scanning data structure, it can be optimized more than the RB tree and remain efficient in a write-only case. However, a boost of particular characteristics can impact others. Therefore, the best way is to prioritize what is important and discard what is not.