

Authors:
(1) Nicholas Farn, Microsoft Corporation {Microsoft Corporation {nifarn@microsoft.com};
(2) Richard Shin, Microsoft Corporation {eush@microsoft.com}.
Table of Links
Conclusion, Reproducibility, and References
D. Nuances comparing prior work
3 EVALUATION METHODOLOGY
Evaluation of a tool-using assistant with ToolTalk consists of two phases. In the first phase, for each conversation, we take all prefixes that end in a user utterance (which could have been preceded by prior user utterances, the tool calls made for those utterances, the results of those calls, and the assistant’s response considering all of the above). We run the assistant with this prefix, where it can either predict a tool call or generate a response given the calls already made and their results; if the assistant predicts a tool call, we execute it using our simulated tool implementations and then provide the assistant with the result. In the second phase, for each conversation prefix, we compare the tool calls predicted for that prefix against its corresponding ground truth, computing the tool invocation recall and incorrect action rate as described below.
3.1 TOOL CALL CORRECTNESS
As described in Section 2.1, for each action tool, we defined a function to compare a predicted and a ground truth invocation of that tool (considering the arguments in the invocations), to help us determine whether a predicted tool call should be considered equivalent to one in the ground truth. For example, if an email is required to be sent to multiple people, we only check that the set of emails are the same instead of requiring the exact same order.
For argument fields that accept free-form natural language inputs, such as message bodies and event descriptions, we compute their embeddings with DistilBERT using sent2vec[2] and check whether their cosine similarity is above 0.9.
For optional arguments, if the ground truth invocation has a value for one, then we compare its value against the one in the predicted invocation; if the ground truth invocation is missing a value for an optional argument, then it is entirely disregarded and the predicted call may have any value for that argument (or none at all) while still being considered correct. For example, the description of a calendar event is an optional argument, and if it is not explicitly mentioned in the conversation, then it is unlikely to impact the correctness of a predicted call whether or not it is filled out.
For the non-action tools (which are generally tools for searching over a database), we do not compare the arguments in the tool calls, but rather compare the execution results of the predicted and ground truth tool calls. They are considered equivalent of the results are identical.
3.2 CONVERSATION SIMULATION
Algorithm 1 shows the general pseudocode for conversation simulation. To simulate a conversation, we first reset the state of the world (e.g. databases get reset to their initial state). For each turn in the ground truth (consisting of a user’s utterance, tool calls for that utterance, and the assistant’s reply),

we provide the information from all previous turns, followed by the current turn’s user utterance, to the model. We then let the model predict as many tool calls as it wants, executing them one at a time until the prediction model produces a reply to the user instead of a tool call.
3.3 INCORRECT ACTIONS
Each tool is labeled as being either an action or not. We consider a tool an action if its execution has the ability to affect the external world such as sending messages or deleting calendar events. In comparison, non-action tools only passively references knowledge from the outside world such as looking up the weather or calling a calculator. We make this distinction between action and nonaction tools because incorrect calls to action tools are much more consequential. For example, an incorrect call to the DeleteAlarm tool could result in the user over-sleeping. While an assistant could theoretically realize that it made an incorrect action tool call and make a different one to reverse its effects, not all actions are reversible.
Thus, during evaluation, we also track “incorrect” actions. We consider an action “incorrect” if the tool called is labeled as an action, it fails to match any call in the ground truth, and if the tool call executed without any errors (including by having the correct number of arguments and passing the correct types).[3]
3.4 METRICS
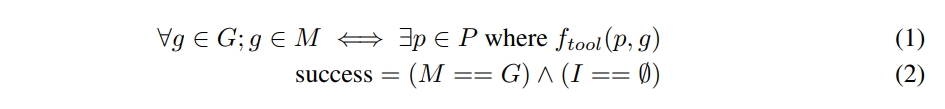
We use the tool call correctness function, ftool, to compare each prediction to all tool calls in the ground truth; as described in Algorithm 2, each ground truth tool call can only match once to a predicted tool call. Given a set of M predictions matching ground truth (defined in equation 1), the set of all predictions P, and the set of all ground truth tool calls G we calculate precision and recall
as |M|/|P| and |M|/|G| respectively. Additionally, we define A as the set of all actions predicted and I as the set of incorrect actions and calculate incorrect action rate as |I|/|A|.
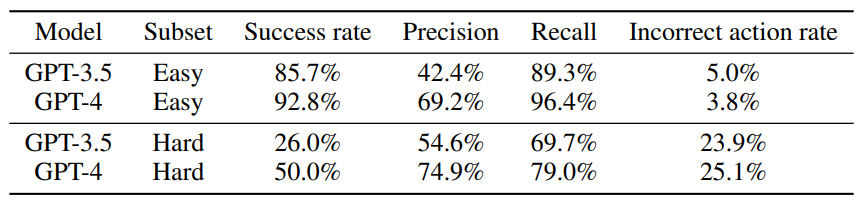
Additionally, we compute success as a boolean value for each conversation, following Equation 2. The assistant succeeds at a conversation if and only if it has perfect recall and no incorrect actions. We take success rate over all conversations as our key metric. Since success rate is a composite of two scores, we keep recall and incorrect action rate as additional metrics to provide more detail. We also include precision as a measure of efficiency in tool prediction; a higher precision indicates that there were fewer predicted tool calls that are unnecessary according to the ground truth.
This paper is available on arxiv under CC 4.0 license.
[2] https://github.com/pdrm83/sent2vec
[3] For the SendEmail and SendMessage tools, we ignore errors which occur due to invalid recipient emails or usernames.